微軟等著告Google ?
微軟花5億美元買下Danger,除為跨入消費性智慧型手機市場外,或許亦欲藉此布局,編織1條阻卻Google Android發展的絆馬索。
口袋深度夠的微軟,在2008年2月1日公開向雅虎提出以總價446億美元收購提議,還等不到雅虎點頭,便又出手並談妥下一個購併:2008年2月11日,微軟在Mobile World Congress開展當天,宣布購併手機軟體與服務公司美商Danger。
Danger是一家典型的矽谷創業公司,在1999年成立,其總部位於帕羅奧多(Palo Alto),原本規劃近期於公開上市。從該公司在2007年12月遞交給美國證管會(SEC)申請IPO的申請表格(Form S-1)來看,Danger原預定以股票代號DNGR在NASDAQ上市籌資1億美元。
該公司最後決定放棄IPO,同意微軟的收購,主要原因有2:其一,受美國次貸風暴影響,企業近期在資本市場籌資不易,Danger若執意IPO,將落得上市價格不佳或籌募金額不如預期的下場;另外,則是微軟出的價格夠漂亮,讓原先陸續投資Danger,共計投入約1.31億美元的股東們感到滿意。
微軟花5億美元高價 只為買另1個手機OS?
這樁購併交易的洽談始於2007年夏天。雖然購併金額未公布,但幾位消息靈通的矽谷業界人士隔天便透過管道,打探出微軟付出5億美元的代價,這價碼比諾基亞(Nokia)以約1.53億美元買下瑞典軟體公司Trolltech高出許多。而Danger與Trolltech這兩家軟體公司在公司人數、年營收及損益方面,規模十分接近
依據Trolltech財報資料顯示,從2007年9月底往前回溯1年,其年營收約2.14億瑞典克朗(折合美元約為3,910萬美元,以1瑞典克朗=0.183美元計算),淨損(net loss)約4,570萬瑞典克朗(約836萬美元),員工數目至2007年底在250人上下。
同一時期,Danger的年營收為5,640萬美元,淨損約1,240萬美元,員工數目近300人,且公司成立至2007年9月底累積虧損已高達1.88億美元。
再從Trolltech與Danger的核心能力、業務或產品來看,這2家公司在專精領域方面亦有類似之處。
Trolltech的2大主力產品,分別為Qt與Qtopia,兩者所佔的營收比例各約為3分之1與3分之2。其中,Qt是跨多種作業平台的應用程式開發架構環境與工具套件,瀏覽器Opera、 3D地圖軟體Google Earth與網路電話軟體Skype等多種著名應用程式皆使用Qt來進行開發;Qtopia則是基於Linux的手持裝置應用環境與使用介面開發平台,Trolltech曾在2006年9月以Qtopia為基礎推出智慧型手機Greenphone(已於2007年10月停售)。
至於Danger的主要業務,則是透過其專屬的手機作業系統、軟體應用開發平台及服務架構解決方案(Danger Platform solution),與行動電信業者合作推出手機與相對應服務,而該公司最大的客戶為T-Mobile USA,雙方自2002年起合作推出Sidekick系列機種與各式行動服務。
雖說微軟目前市值高達2,600億美元、手頭的現金與隨時可變現的短期投資合計就超過210億美元,但在微軟發展多年的Windows Mobile(WM),近年於智慧型手機領域頗有斬獲的情況下,以一般認為高於市場行情不少的5億美元,不會只是為了買下另1個手機作業系統。
擺脫WM商務用途侷限 藉Danger跨入消費性市場
微軟的WM平台是從原先專攻PDA市場的Pocket PC所演進過來,其特色便是與PC版的Windows作業系統及應用程式(特別是用於辦公室應用的Word、Excel、Outlook等Office軟體)有良好的相容性與連結性,因而透過此平台所推出的智慧型手機,截至目前絕大多數也都是從商務應用的角度切入。
相較之下WM平台在消費性智慧型手機市場,並無太大建樹,不僅遠遠落於透過諾基亞手機攻佔智慧型手機平台全球霸主地位的Symbian 之後,2007年的當紅炸子「機」iPhone在美國市場推出才半年多,也把WM甩到其後。
由於Sidekick手機所提供的即時訊息、網頁瀏覽、社群交友等功能或服務,為T-Mobile USA在美國贏得眾多20歲上下年輕族群的喜好(依Danger發布的數據Sidekick系列機種擁有超過90萬的用戶),而這正是WM平台甚為薄弱的一環,因此購併Danger的行動,市場上普遍認為可補強微軟手機作業系統在消費性市場布局。
微軟專利絆馬索 拖延Google Android發展
微軟買下Danger的原因,除前述理由外,有另1種陰謀論,那就是為阻卻或至少拖延Google的Android手機作業平台的發展。
有此說法,乃因在Google內部領導Android平台開發的Andy Rubin,不僅是Danger的創辦人之一,更擔任過該公司CEO與總裁,而Danger公司於2001年發表、當時名為Hiptop的手機暨對應服務平台架構(即為後來的Danger Platform),可說有很大一部分是Rubin的心血結晶。
雖說Andy Rubin早已於2004年離開Danger公司,但難保在他在發展Android平台時,未帶入當時發展Hiptop的部分想法。特別是未來在Google將Android原始碼公布後,若微軟檢視後發現其中只要有些許技術或作法,牽涉到Danger握有的專利,微軟即可宣稱Google有侵權嫌疑,甚至藉此一狀告上法庭。
一旦走上法庭,不論最終訴訟結果為何,在此過程中微軟已經有效降低Android支持者及消費者的信心,達到拖延甚至阻卻Google藉由Android 揮軍行動領域之目的。
微軟愛用FUD戰術 打擊競爭對手
藉由專利訴訟或宣稱遭侵權,在市場上營造恐懼、不確定性及質疑(Fear、uncertainty and doubt;FUD)的氛圍,來打擊或拖延對手陣營的商業合作或發展,一向是微軟的拿手戲,近年來掀起軒然大波的1樁「傑作」,就是針對開放原始碼陣營-微軟在2007年5月宣稱Linux這類的開放原始碼軟體,所侵犯微軟的專利高達235項。
從90年代起被冠上最善用FUD市場策略的微軟,這回買下Danger,會不會藉此再度使出這項絕招來對付Google,拭目以待。
2008年2月25日 星期一
2008年2月20日 星期三
[分享]以3D畫面為主的瀏覽器 Space Time
擷取自:http://blog.pixnet.net/goodjs/post/14067446
今天逛到了好玩的東西 所以打算又要作圖來教大家
以及讓大家先看看 使用這個瀏覽器的畫面
就像他的名稱一樣 Space
很有立體的空間 以及他主打的地方就是那些知名的影音網站 然後,他是個瀏覽器。
ex. Youtube, Google News, Yahoo Image, Google Image, 最棒的是eBay US, 當你在網路上找東西的時候,那畫面真的以為置身在大賣場。還有一些知名的RSS網站
這些網站將會以3D的畫面呈現 真的是一大感官享受 不過整個設計起來 很像 fichey 這個網站,因為風格差不多,只是Space Time 有更多選擇,而且是個瀏覽器。
1. 第一步 一定是下載阿 不然怎麼玩

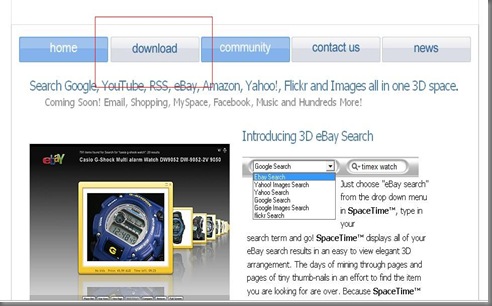
2.進入下載畫面 以及輸入你的電子郵件信箱
這裡有提到使用這個軟體所需要的配備 512記憶體 128MB的顯示卡 CPU等等的 自己看吧 因為我不會翻這些電腦術語XD

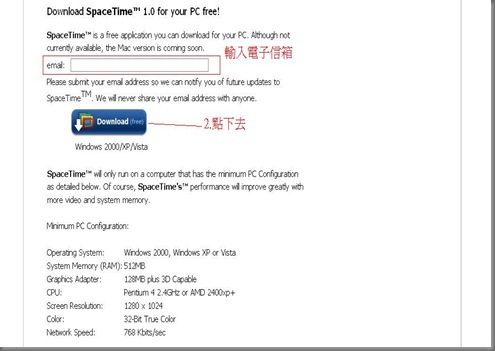
3.下載完安裝後 點擊圖示 就會出現下面這個畫面

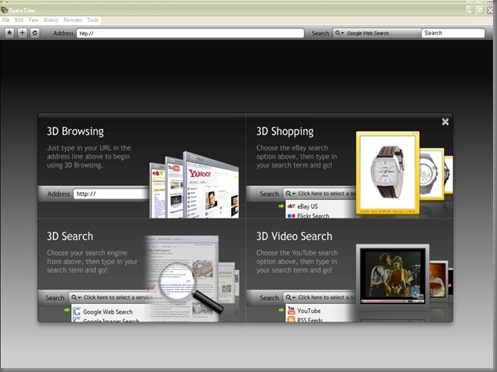
4.在右上角 有個搜尋列 點下去有一個下拉式選單 就是我在前文提到的網站 當然還有更多啦!!

5.這是我用eBay搜尋Bose音響的畫面 很讚吧!!!

6.下面是我用Google News 搜尋美國民主黨候選人 Obama的新聞

7. 這是我用亞馬遜搜尋 戒指 出現的畫面 eBay 的畫面比較華麗

8.這是Youtube的畫面 我搜尋Taiwan 的畫面

使用心得:當我用eBay的時候 真的覺得超讚的! 只是可能是我電腦老了,常常跑不快,另外他因為一次要開很多畫面,所以會花一點時間。Flicker的搜尋似乎有點問題,因為我搜尋flicker常常程式跑不動。 整個下來還很陽春 也相信有很多Bug,不過我相信這個瀏覽器軟體肯定會更好,搞不好以後還會出火狐版的,那就更棒了!你要拿這瀏覽器純粹逛網頁也是可以的喔! 畫面很精緻,可惜還有很多地方需要改進的。
分享至PLURK 噗浪
分享至FACEBOOK 臉書
今天逛到了好玩的東西 所以打算又要作圖來教大家
以及讓大家先看看 使用這個瀏覽器的畫面
就像他的名稱一樣 Space
很有立體的空間 以及他主打的地方就是那些知名的影音網站 然後,他是個瀏覽器。
ex. Youtube, Google News, Yahoo Image, Google Image, 最棒的是eBay US, 當你在網路上找東西的時候,那畫面真的以為置身在大賣場。還有一些知名的RSS網站
這些網站將會以3D的畫面呈現 真的是一大感官享受 不過整個設計起來 很像 fichey 這個網站,因為風格差不多,只是Space Time 有更多選擇,而且是個瀏覽器。
1. 第一步 一定是下載阿 不然怎麼玩
2.進入下載畫面 以及輸入你的電子郵件信箱
這裡有提到使用這個軟體所需要的配備 512記憶體 128MB的顯示卡 CPU等等的 自己看吧 因為我不會翻這些電腦術語XD
3.下載完安裝後 點擊圖示 就會出現下面這個畫面
4.在右上角 有個搜尋列 點下去有一個下拉式選單 就是我在前文提到的網站 當然還有更多啦!!
5.這是我用eBay搜尋Bose音響的畫面 很讚吧!!!
6.下面是我用Google News 搜尋美國民主黨候選人 Obama的新聞
7. 這是我用亞馬遜搜尋 戒指 出現的畫面 eBay 的畫面比較華麗
8.這是Youtube的畫面 我搜尋Taiwan 的畫面
使用心得:當我用eBay的時候 真的覺得超讚的! 只是可能是我電腦老了,常常跑不快,另外他因為一次要開很多畫面,所以會花一點時間。Flicker的搜尋似乎有點問題,因為我搜尋flicker常常程式跑不動。 整個下來還很陽春 也相信有很多Bug,不過我相信這個瀏覽器軟體肯定會更好,搞不好以後還會出火狐版的,那就更棒了!你要拿這瀏覽器純粹逛網頁也是可以的喔! 畫面很精緻,可惜還有很多地方需要改進的。
英特爾提前釋平台 低價PC 5月開戰
擷取自: http://www.digitimes.com.tw/n/article.asp?id=0000082251_A7Z30I10GF67IKI0SCH0X
低價PC話題在Eee PC、OLPC及Classmate PC等產品熱銷帶動下,市場話題依舊不墜,而為能取得市場先機、避免消費者熱度減退,據PC業者表示,處理器龍頭英特爾(Intel)已決定將低價平台推出時程提前,由原先規劃的2008年第3季,提早至5月就正式發,屆時多家業者亦會同步發表低價筆記型電腦(NB)或桌上型電腦(DT),英特爾策略牽動各廠布局。
Eee PC上市迄今4個月,細膩的市場區隔策略成功開創全新PC領域,同時也迅速打開國際品牌知名度,吸引眾多PC相關業者也跟進開發行列,英特爾也特為低價PC打造全新且規格統一的平台,2007年11月即陸續釋出專用處理器Diamondville訊息,期望藉由各大PC業者爭食大餅,進一步拉升產品出貨,取得低價PC市場絕對優勢。
Eee PC等低價產品目前在PC市場熱度仍未退卻,包括宏碁、微星、技嘉及惠普等多家大廠看好此一前景,已準備推出同級產品,推出時程則視英特爾何時正式發布低價平台,而據PC業者透露,英特爾原先規劃會於2008年第3季推出採用Diamondville處理器的DT及NB平台,但經詳細評估推出時間太長,恐失市場先機,加上合作夥伴已等不及進入此一市場,決定將推出時程往前推進2個月。
據英特爾最新規劃,專屬低價PC平台採用Diamondville處理器,包括針對超低價DT市場的全新「Shelton'08」,以及為低價、簡易NB量身打造的「Basic Mobile Platform」,暫定提前至5月就會發表,6月台北COMPUTEX即會看到各家爭鳴市況。
「Basic Platform」採用45奈米製程的Diamondville單核心Single Core(SC)處理器,擁有2 Threads(單一核心可同時間執行2個指令),型號為「N270」(1.6GHz/533MHz FSB/512K Cache),晶片組則為945GSE搭配南橋ICH-7M(Calistoga Smaill Form Factor Chipset),搭配微軟(Microsoft)簡易版作業系統XP或Linux。
「Shelton'08」DT平台則亦採用Diamondville,不過擁有SC及雙核心Dual Core(DC)版本;單核心型號為230(1.6GHz/533MHz/512K/TDP 4W),雙核心型號暫定3xx,規格未明。
NB業者認為,低價PC市場提前至5月開打,戰況激烈已可預見,可預見的是不論哪款產品熱賣,英特爾平台永遠是最大贏家,因此在未來3年內,該公司擬在亞洲投資10億美元,支持PC業者共同推動低價輕便電腦,以及MID(Mobile Internet Device)平台,使其在新興市場普及化。
而為在低價PC此全新戰場勝出,各廠研發團隊現正絞盡腦汁推出創出技術,與對手作出區隔,在處理器平台及簡易版XP及Linux作業系統各廠大家皆在同一起跑點上,螢幕、記憶體、儲存裝置及外型設計等規格,加上各自所擁有的行銷通路及公關宣傳實力成為勝負關鍵所在。
值得一提的是,英特爾低價平台只是其市場細分計畫的一環,英特爾(Intel)中國區總經理楊敘表示,電腦將越來越像手機,電腦依應用功能細分也成為趨勢,因此未來電腦一定會像手機一樣產生運用區隔,最低階的就是MID這種網路終端,接著是Shelton平台的低價輕便電腦,之後到主流功能的桌上型電腦(DT)和筆記型電腦(NB),最後是功能強大的4核心桌上型電腦。然而,楊敘也強調,目前還並沒有必要討論到底市場購買哪種電腦的人最多,因此英特爾將提供全系列的產品,以滿足不同市場的需求。
分享至PLURK 噗浪
分享至FACEBOOK 臉書
低價PC話題在Eee PC、OLPC及Classmate PC等產品熱銷帶動下,市場話題依舊不墜,而為能取得市場先機、避免消費者熱度減退,據PC業者表示,處理器龍頭英特爾(Intel)已決定將低價平台推出時程提前,由原先規劃的2008年第3季,提早至5月就正式發,屆時多家業者亦會同步發表低價筆記型電腦(NB)或桌上型電腦(DT),英特爾策略牽動各廠布局。
Eee PC上市迄今4個月,細膩的市場區隔策略成功開創全新PC領域,同時也迅速打開國際品牌知名度,吸引眾多PC相關業者也跟進開發行列,英特爾也特為低價PC打造全新且規格統一的平台,2007年11月即陸續釋出專用處理器Diamondville訊息,期望藉由各大PC業者爭食大餅,進一步拉升產品出貨,取得低價PC市場絕對優勢。
Eee PC等低價產品目前在PC市場熱度仍未退卻,包括宏碁、微星、技嘉及惠普等多家大廠看好此一前景,已準備推出同級產品,推出時程則視英特爾何時正式發布低價平台,而據PC業者透露,英特爾原先規劃會於2008年第3季推出採用Diamondville處理器的DT及NB平台,但經詳細評估推出時間太長,恐失市場先機,加上合作夥伴已等不及進入此一市場,決定將推出時程往前推進2個月。
據英特爾最新規劃,專屬低價PC平台採用Diamondville處理器,包括針對超低價DT市場的全新「Shelton'08」,以及為低價、簡易NB量身打造的「Basic Mobile Platform」,暫定提前至5月就會發表,6月台北COMPUTEX即會看到各家爭鳴市況。
「Basic Platform」採用45奈米製程的Diamondville單核心Single Core(SC)處理器,擁有2 Threads(單一核心可同時間執行2個指令),型號為「N270」(1.6GHz/533MHz FSB/512K Cache),晶片組則為945GSE搭配南橋ICH-7M(Calistoga Smaill Form Factor Chipset),搭配微軟(Microsoft)簡易版作業系統XP或Linux。
「Shelton'08」DT平台則亦採用Diamondville,不過擁有SC及雙核心Dual Core(DC)版本;單核心型號為230(1.6GHz/533MHz/512K/TDP 4W),雙核心型號暫定3xx,規格未明。
NB業者認為,低價PC市場提前至5月開打,戰況激烈已可預見,可預見的是不論哪款產品熱賣,英特爾平台永遠是最大贏家,因此在未來3年內,該公司擬在亞洲投資10億美元,支持PC業者共同推動低價輕便電腦,以及MID(Mobile Internet Device)平台,使其在新興市場普及化。
而為在低價PC此全新戰場勝出,各廠研發團隊現正絞盡腦汁推出創出技術,與對手作出區隔,在處理器平台及簡易版XP及Linux作業系統各廠大家皆在同一起跑點上,螢幕、記憶體、儲存裝置及外型設計等規格,加上各自所擁有的行銷通路及公關宣傳實力成為勝負關鍵所在。
值得一提的是,英特爾低價平台只是其市場細分計畫的一環,英特爾(Intel)中國區總經理楊敘表示,電腦將越來越像手機,電腦依應用功能細分也成為趨勢,因此未來電腦一定會像手機一樣產生運用區隔,最低階的就是MID這種網路終端,接著是Shelton平台的低價輕便電腦,之後到主流功能的桌上型電腦(DT)和筆記型電腦(NB),最後是功能強大的4核心桌上型電腦。然而,楊敘也強調,目前還並沒有必要討論到底市場購買哪種電腦的人最多,因此英特爾將提供全系列的產品,以滿足不同市場的需求。
Globalspec--區域性搜索例子
How do we to realize "perfect search"?
為了實現完美搜尋,我們先來看看區域特有性搜尋吧!! Globalspec 就是區域性搜尋中最好的一個例子~
首先,我們先來介紹Globalspec 是什麼吧?
WWW.GLOBALSPEC.COM
全球最大工程技術類買家服務的採購網站平臺GlobalSpec,2O06年3月正式進入大中華地區,為兩岸供應商提供有效的全球市場拓展解決方案,攜手開拓全球工業電子技術市場。
Globalspec成立於1996年,目前擁有330萬註冊用戶,內容涵蓋20,000多類電子目錄、180多萬種產品,以及超過1.38億種產品規格。採買工程師和技術工程專家群可透過Globalspec網站,線上尋找工程技術資訊和電子工業產品零配件資源。
由於GlobalSpec定位是服務專業的技術型買家,因此滿足這群採買工程師的需求成為GlobalSpec的核心競爭力。Globalspec大中華區總經理童秋喜表示,技術型買家和一般商品買家不同,以電子零組件為例,採購工程師所關注的是電氣、物理或化學特性所呈現的產品規格,而不是僅關注價格方面
而GlobalSpec又如何滿足技術型買家的需求?
首先技術型買家可以線上経簡易3步驟3O秒成為註冊用戶,再根據對產品的特定需要,通過設定各種規格迅速縮小搜索範圍,直到找到最符合要求的產品.這就是経註冊的獨創技術 SpecSearch (規格搜索).
SpecSearch 規格搜索己経跳脫第一代B2B電子商務平臺資訊流端單純產品搜尋功能.尤其今日的採購網充斥有效無效的海量資訊,”精確結果”成為網路搜尋者最大的希望. 對於這群專業的技術型買家, GlobalSepc所能提供的服務遠遠超越Google之於一般網路使用者.
GlobalSpec標出了大約100萬個他們認為包含工程領域訊息的網址,並對這些網址進行索引。
比如說:如果你search "空氣動力學"的話,也會得到下列相關術語的搜尋結果---飛行器,飛行機械原理、直升機空氣動力學、理論空氣動力學....等
然而,GlobalSpec並不只對註冊用戶開放,每個人都可以使用它,這樣便為公眾建立一個工程訊息智慧基地。
GlobalSpec積極進軍大中華區市場——擁有330萬註冊用戶 工程類專業搜索引擎與採購網站平臺
分享至PLURK 噗浪
分享至FACEBOOK 臉書
為了實現完美搜尋,我們先來看看區域特有性搜尋吧!! Globalspec 就是區域性搜尋中最好的一個例子~
首先,我們先來介紹Globalspec 是什麼吧?
WWW.GLOBALSPEC.COM
全球最大工程技術類買家服務的採購網站平臺GlobalSpec,2O06年3月正式進入大中華地區,為兩岸供應商提供有效的全球市場拓展解決方案,攜手開拓全球工業電子技術市場。
Globalspec成立於1996年,目前擁有330萬註冊用戶,內容涵蓋20,000多類電子目錄、180多萬種產品,以及超過1.38億種產品規格。採買工程師和技術工程專家群可透過Globalspec網站,線上尋找工程技術資訊和電子工業產品零配件資源。
由於GlobalSpec定位是服務專業的技術型買家,因此滿足這群採買工程師的需求成為GlobalSpec的核心競爭力。Globalspec大中華區總經理童秋喜表示,技術型買家和一般商品買家不同,以電子零組件為例,採購工程師所關注的是電氣、物理或化學特性所呈現的產品規格,而不是僅關注價格方面
而GlobalSpec又如何滿足技術型買家的需求?
首先技術型買家可以線上経簡易3步驟3O秒成為註冊用戶,再根據對產品的特定需要,通過設定各種規格迅速縮小搜索範圍,直到找到最符合要求的產品.這就是経註冊的獨創技術 SpecSearch (規格搜索).
SpecSearch 規格搜索己経跳脫第一代B2B電子商務平臺資訊流端單純產品搜尋功能.尤其今日的採購網充斥有效無效的海量資訊,”精確結果”成為網路搜尋者最大的希望. 對於這群專業的技術型買家, GlobalSepc所能提供的服務遠遠超越Google之於一般網路使用者.
GlobalSpec標出了大約100萬個他們認為包含工程領域訊息的網址,並對這些網址進行索引。
比如說:如果你search "空氣動力學"的話,也會得到下列相關術語的搜尋結果---飛行器,飛行機械原理、直升機空氣動力學、理論空氣動力學....等
然而,GlobalSpec並不只對註冊用戶開放,每個人都可以使用它,這樣便為公眾建立一個工程訊息智慧基地。
GlobalSpec積極進軍大中華區市場——擁有330萬註冊用戶 工程類專業搜索引擎與採購網站平臺
IBM能否成為企業搜索市場的Google----Webfountain
《商業周刊》網站日前刊登了分析文章指出,就在Google上市成?人們談論最多的話題之時,科技巨頭IBM在大力推崇其名?WebFountain的網路搜索技術。Google的搜尋範圍能力和IBM的WebFountain技術都有什麼不同呢?我們不妨來聽聽IBM該業務兩位主管的說法。
8年前,斯坦福大學兩名電腦專業的學生開始在網路搜索技術領域內展開了新的探
索,並希望能與當時也在進行相關技術開發的IBM決一勝負。這兩名學生改變了此前僅僅在文檔中進行搜索的傳統方式,而採取了提供互聯網鏈結的全新方案。這兩名學生後來創建了著名的Google公司,並準備在今後數月內進行它的首次公開募股(IPO)活動。
與Google相比,IBM的網路搜索技術似乎已經從公眾的視線中消失。儘管如此,IBM多年來卻從沒有停止自身網路搜索技術的研發工作。在經過七年的秘密行動之後,IBM于去年正式向外公佈了它名稱: WebFountain的網路搜索技術。IBM稱,它的這項技術具備了高智慧篩選搜索資訊的特點。
眾所周知,目前絕大部分搜索引擎所採用的方式是通過關鍵字及相關網頁鏈結來實現。與這種傳統的方式不同,WebFountain將可以提供基於文章觀點的搜索方式。舉例來說,通過WebFountain技術,你不僅可以來搜索與索尼CyberShot數位相機的相關資訊,你還可以鍵入“人們對CyberShot產品品質的看法?”這樣的句子,從而得到與該產品有關見解的文章資訊。
由此可見,WebFountain技術的終極目標是想給網路搜索技術帶來全新的變革。就目前而言,大多數網路搜索還無法具備記憶功能。換句話說,搜索者進行過相關主題搜索後,在他再次進行此類主題搜索活動時,搜索引擎不但無法提供他以前所搜索過的相關資訊,而且也無法就此主題的相關進展情況進行合理的分析。而WebFountain技術就是想要針對這些不足而提出自己的解決方案。
IBM稱,它的WebFountain技術並不是想取代Google目前的市場位置,而只是想提供一種更智慧的搜索服務方式。就這個問題,《商業周刊》記者採訪了IBM WebFountain業務總負責人丹-格魯爾(Dan Gruhl)及首席科學家安德魯-湯姆金斯(Andrew Tomkins)。下面就是這次採訪的摘要。
問:?何你們IBM目前急於給自己挂上搜索服務商的招牌?
格魯爾:雖然目前已有的搜索技術使我們獲取資訊更加容易,但這還僅僅是個開始。如何對各種資訊的進展情況進行智慧分析,這就是我們開發WebFountain技術的基本目的之一。
問:那WebFountain的長期目標是什麼?與Google的技術相比,你們是否也會在今後提供一種全能型的搜索引擎服務?
湯姆金斯:我們採取了不同的搜索結果解決方案。我們更願意搜索者在進行搜索時,他所使用的搜索語言更豐富,也更有形象。當然這需要使用者花上一定的時間來熟悉WebFountain的技術特徵,這樣才能最大程度地利用這一新技術。我們認為,如果說傳統的搜索技術向人們提供了網路上“有什麼樣的資訊”這一功能,而WebFountain則向人們回答了網上“為何會有這麼多的相關新資訊”這一新問題。
問:那從長期目標看,你們的WebFountain業務是否會與Google的業務出現重疊的情況?
湯姆金斯:我們的長期目標是,我們將力爭能實現每20分鐘就對相關網頁資訊做到隨時更新。我們的這項業務能在每分鐘內回答某個特定問題的最新進展。由此可見,我們WebFountain所面向的是一個與Google迥然不同的市場。
問:那將來普通消費者是否也能享受到你們WebFountain所提供的最新服務?
格魯爾:如果有人願意做這方面的開發工作,我們當然不會反對。事實上是普通的網民正成?網上搜索的主力軍,這種趨勢還會進一步發展下去
那什麼是 Webfountain呢??
WebFountain is an Internet analytics engine implemented by IBM for the study of unstructured data on the World Wide Web. IBM describes WebFountain as:
. . . a set of research technologies that collect, store and analyze massive amounts of unstructured and semi-structured text. It is built on an open, extensible platform that enables the discovery of trends, patterns and relationships from data.[1]
The project represents one of the first comprehensive attempts to catalog and interpret the unstructured data of the Web in a continuous fashion. To this end its supporting researchers at IBM have investigated new systems for the precise retrieval of subsets of the information on the Web, real-time trend analysis, and meta-level analysis of the available information of the Web.
Factiva, an information retrieval company owned by Dow Jones and Reuters, licensed WebFountain in September 2003, and has been building software which utilizes the WebFountain engine to gauge corporate reputation.[2] Factiva reportedly offers yearly subscriptions to the service for $200,000. Factiva has since decided to explore other technologies, and has severed its relationship with WebFountain.
WebFountain is developed at IBM's Almaden research campus in the Bay Area of California.
相關的文章下載:
1. WebFountain
2. WebFountain—today’s key to proactive management
3. Sentiment Mining in WebFountain
據IBM資訊管理集團的總經理珍妮特表示稱,IBM一直在悄悄地開發資料存儲軟體,將能夠極大地提高企業查找“分散”在網路上的各種文檔。
新的搜索軟體和其他資訊獲取軟體,彰顯出IBM退出PC等廉價硬體業務領域、轉向高利潤的軟體、服務業務的戰略。珍妮特說,開發新的搜索軟體將加快IBM由關聯資料庫廠商向資訊管理軟體提供商轉型的速度。
珍妮特表示,與資料庫相關的搜索軟體將使企業客戶能夠以XML格式存儲文檔,這將大大提高文檔的查找速度。該搜索工具的α版正在由約30家客戶進行測試,正式版將于明年下半年完成。IBM還沒有為該搜索工具命名,或透露有關如何封裝的資訊。
珍妮特說,關聯資料庫是企業的“中流砥柱”,主要用於存儲各種記錄和交易資料。但約85%的企業資料被存儲在所謂的非結構化資料源中??例如字處理文檔、XML文檔、圖像,這就給資料的查找帶來了困難。
通過收購和對搜索技術的大規模投資,IBM正在悄悄地成為搜索技術領域的領頭羊,其目標是使對企業網路的搜索象使用Google搜索互聯網那樣常見和方便。
通常情況下,企業的員工通過口頭傳達的方式瞭解業務報告,或者他們會重新編寫一份已經存儲在企業伺服器上的報告。對現有報告“倉庫”進行搜索將大大加快員工瞭解業務報告的過程,還可能減少不必要的資訊冗餘。
分析人士指出,隨著業務範圍的擴展,IBM將與微軟、甲骨文,以及其他一些規模較小的專業企業搜索公司發生激烈競爭。甲骨文的OracleFiles10g能夠幫助用戶查找以文本方式存儲的文檔,將使甲骨文的優勢擴展到資料庫之外的領域;微軟一直在積極地開發搜索技術,WinFS檔系統能夠簡化對存儲在PC上的不同類型內容的查找。另外,微軟也銷售內容管理軟體,並在開發新的搜索引擎,挑戰Google和雅虎。幾家小公司也推出了基於文本的搜索軟體,使企業客戶對它們的網路進行搜索。
儘管信息量要少得多,但對企業網路進行搜索要比對互聯網進行搜索複雜得多。與互聯網不同的是,企業的資訊可能存儲在多個地方,而且以多種格式進行存儲。另外,企業客戶還要求穩定的存儲系統,需要遵守一些監管條例。臺式機搜索與互聯網搜索的另一個重大不同之處是,在企業網路中搜索需要從多個資料源收集資訊,並使它們之間發生關聯。
IDC估計,去年企業搜索市場達到了6.2億美元,增長幅度達到了20%。IDC的分析師菲爾德曼說,由於不同的廠商都希望在企業資訊管理市場上分一杯羹,傳統的內容管理提供商和專業搜索廠商之間的碰撞是必然的。內容管理和搜索廠商以前合作得非常愉快,但現在這二個市場融合了。這一新興的資訊架構正是IBM、甲骨文以及其他廠商追逐的目標。
IBM正在通過收購和利用自己的研發成果開發內容管理和搜索產品。目前,在IBM的研發部門約有300名工程師在從事與搜索相關的專案的研究。WebFountain專案旨在改進簡單的文本匹配搜索規則,並通過檢查句子中各單詞間的關係發現文檔中更多的含義。IBM已經開發了一個名為Marvel的搜索引擎原型產品,能夠在視頻內容中找到特定的場景。
今年早些時候DB2InformationIntegrator的發售,使得IBM在企業搜索市場上取得了一席之地。IBM還計畫改變在資料庫中存儲XML文檔的方式,從而提高搜索能力。
川崎汽車公司負責資訊管理的主管維克多說,IBM的技術非常有吸引力,因為它能夠處理不同類型的資訊,適應不同的運行環境。他關注過的一些小公司的技術只能搜索範圍要窄得多的資訊類型。
珍妮特說,同時管理結構化資料和電子郵件、文本文檔等非結構化資料代表著內容管理產業的未來。IBM的策略是開發面向大企業客戶的全功能資訊管理平臺。菲爾德曼表示,其他公司銷售的產品只能解決不太複雜的技術。
儘管IBM在關聯資料庫市場上是一家重量級廠商,但其大多數與搜索相關的工作仍然處於研發階段。維克多表示,IBM在企業搜索市場上最大的挑戰可能是其形象,而不是技術。當客戶想到搜索時,它們不會想到IBM。IBM能夠使自己被客戶接受為搜索服務提供商嗎?
分享至PLURK 噗浪
分享至FACEBOOK 臉書
8年前,斯坦福大學兩名電腦專業的學生開始在網路搜索技術領域內展開了新的探
索,並希望能與當時也在進行相關技術開發的IBM決一勝負。這兩名學生改變了此前僅僅在文檔中進行搜索的傳統方式,而採取了提供互聯網鏈結的全新方案。這兩名學生後來創建了著名的Google公司,並準備在今後數月內進行它的首次公開募股(IPO)活動。
與Google相比,IBM的網路搜索技術似乎已經從公眾的視線中消失。儘管如此,IBM多年來卻從沒有停止自身網路搜索技術的研發工作。在經過七年的秘密行動之後,IBM于去年正式向外公佈了它名稱: WebFountain的網路搜索技術。IBM稱,它的這項技術具備了高智慧篩選搜索資訊的特點。
眾所周知,目前絕大部分搜索引擎所採用的方式是通過關鍵字及相關網頁鏈結來實現。與這種傳統的方式不同,WebFountain將可以提供基於文章觀點的搜索方式。舉例來說,通過WebFountain技術,你不僅可以來搜索與索尼CyberShot數位相機的相關資訊,你還可以鍵入“人們對CyberShot產品品質的看法?”這樣的句子,從而得到與該產品有關見解的文章資訊。
由此可見,WebFountain技術的終極目標是想給網路搜索技術帶來全新的變革。就目前而言,大多數網路搜索還無法具備記憶功能。換句話說,搜索者進行過相關主題搜索後,在他再次進行此類主題搜索活動時,搜索引擎不但無法提供他以前所搜索過的相關資訊,而且也無法就此主題的相關進展情況進行合理的分析。而WebFountain技術就是想要針對這些不足而提出自己的解決方案。
IBM稱,它的WebFountain技術並不是想取代Google目前的市場位置,而只是想提供一種更智慧的搜索服務方式。就這個問題,《商業周刊》記者採訪了IBM WebFountain業務總負責人丹-格魯爾(Dan Gruhl)及首席科學家安德魯-湯姆金斯(Andrew Tomkins)。下面就是這次採訪的摘要。
問:?何你們IBM目前急於給自己挂上搜索服務商的招牌?
格魯爾:雖然目前已有的搜索技術使我們獲取資訊更加容易,但這還僅僅是個開始。如何對各種資訊的進展情況進行智慧分析,這就是我們開發WebFountain技術的基本目的之一。
問:那WebFountain的長期目標是什麼?與Google的技術相比,你們是否也會在今後提供一種全能型的搜索引擎服務?
湯姆金斯:我們採取了不同的搜索結果解決方案。我們更願意搜索者在進行搜索時,他所使用的搜索語言更豐富,也更有形象。當然這需要使用者花上一定的時間來熟悉WebFountain的技術特徵,這樣才能最大程度地利用這一新技術。我們認為,如果說傳統的搜索技術向人們提供了網路上“有什麼樣的資訊”這一功能,而WebFountain則向人們回答了網上“為何會有這麼多的相關新資訊”這一新問題。
問:那從長期目標看,你們的WebFountain業務是否會與Google的業務出現重疊的情況?
湯姆金斯:我們的長期目標是,我們將力爭能實現每20分鐘就對相關網頁資訊做到隨時更新。我們的這項業務能在每分鐘內回答某個特定問題的最新進展。由此可見,我們WebFountain所面向的是一個與Google迥然不同的市場。
問:那將來普通消費者是否也能享受到你們WebFountain所提供的最新服務?
格魯爾:如果有人願意做這方面的開發工作,我們當然不會反對。事實上是普通的網民正成?網上搜索的主力軍,這種趨勢還會進一步發展下去
那什麼是 Webfountain呢??
WebFountain is an Internet analytics engine implemented by IBM for the study of unstructured data on the World Wide Web. IBM describes WebFountain as:
. . . a set of research technologies that collect, store and analyze massive amounts of unstructured and semi-structured text. It is built on an open, extensible platform that enables the discovery of trends, patterns and relationships from data.[1]
The project represents one of the first comprehensive attempts to catalog and interpret the unstructured data of the Web in a continuous fashion. To this end its supporting researchers at IBM have investigated new systems for the precise retrieval of subsets of the information on the Web, real-time trend analysis, and meta-level analysis of the available information of the Web.
Factiva, an information retrieval company owned by Dow Jones and Reuters, licensed WebFountain in September 2003, and has been building software which utilizes the WebFountain engine to gauge corporate reputation.[2] Factiva reportedly offers yearly subscriptions to the service for $200,000. Factiva has since decided to explore other technologies, and has severed its relationship with WebFountain.
WebFountain is developed at IBM's Almaden research campus in the Bay Area of California.
相關的文章下載:
1. WebFountain
2. WebFountain—today’s key to proactive management
3. Sentiment Mining in WebFountain
據IBM資訊管理集團的總經理珍妮特表示稱,IBM一直在悄悄地開發資料存儲軟體,將能夠極大地提高企業查找“分散”在網路上的各種文檔。
新的搜索軟體和其他資訊獲取軟體,彰顯出IBM退出PC等廉價硬體業務領域、轉向高利潤的軟體、服務業務的戰略。珍妮特說,開發新的搜索軟體將加快IBM由關聯資料庫廠商向資訊管理軟體提供商轉型的速度。
珍妮特表示,與資料庫相關的搜索軟體將使企業客戶能夠以XML格式存儲文檔,這將大大提高文檔的查找速度。該搜索工具的α版正在由約30家客戶進行測試,正式版將于明年下半年完成。IBM還沒有為該搜索工具命名,或透露有關如何封裝的資訊。
珍妮特說,關聯資料庫是企業的“中流砥柱”,主要用於存儲各種記錄和交易資料。但約85%的企業資料被存儲在所謂的非結構化資料源中??例如字處理文檔、XML文檔、圖像,這就給資料的查找帶來了困難。
通過收購和對搜索技術的大規模投資,IBM正在悄悄地成為搜索技術領域的領頭羊,其目標是使對企業網路的搜索象使用Google搜索互聯網那樣常見和方便。
通常情況下,企業的員工通過口頭傳達的方式瞭解業務報告,或者他們會重新編寫一份已經存儲在企業伺服器上的報告。對現有報告“倉庫”進行搜索將大大加快員工瞭解業務報告的過程,還可能減少不必要的資訊冗餘。
分析人士指出,隨著業務範圍的擴展,IBM將與微軟、甲骨文,以及其他一些規模較小的專業企業搜索公司發生激烈競爭。甲骨文的OracleFiles10g能夠幫助用戶查找以文本方式存儲的文檔,將使甲骨文的優勢擴展到資料庫之外的領域;微軟一直在積極地開發搜索技術,WinFS檔系統能夠簡化對存儲在PC上的不同類型內容的查找。另外,微軟也銷售內容管理軟體,並在開發新的搜索引擎,挑戰Google和雅虎。幾家小公司也推出了基於文本的搜索軟體,使企業客戶對它們的網路進行搜索。
儘管信息量要少得多,但對企業網路進行搜索要比對互聯網進行搜索複雜得多。與互聯網不同的是,企業的資訊可能存儲在多個地方,而且以多種格式進行存儲。另外,企業客戶還要求穩定的存儲系統,需要遵守一些監管條例。臺式機搜索與互聯網搜索的另一個重大不同之處是,在企業網路中搜索需要從多個資料源收集資訊,並使它們之間發生關聯。
IDC估計,去年企業搜索市場達到了6.2億美元,增長幅度達到了20%。IDC的分析師菲爾德曼說,由於不同的廠商都希望在企業資訊管理市場上分一杯羹,傳統的內容管理提供商和專業搜索廠商之間的碰撞是必然的。內容管理和搜索廠商以前合作得非常愉快,但現在這二個市場融合了。這一新興的資訊架構正是IBM、甲骨文以及其他廠商追逐的目標。
IBM正在通過收購和利用自己的研發成果開發內容管理和搜索產品。目前,在IBM的研發部門約有300名工程師在從事與搜索相關的專案的研究。WebFountain專案旨在改進簡單的文本匹配搜索規則,並通過檢查句子中各單詞間的關係發現文檔中更多的含義。IBM已經開發了一個名為Marvel的搜索引擎原型產品,能夠在視頻內容中找到特定的場景。
今年早些時候DB2InformationIntegrator的發售,使得IBM在企業搜索市場上取得了一席之地。IBM還計畫改變在資料庫中存儲XML文檔的方式,從而提高搜索能力。
川崎汽車公司負責資訊管理的主管維克多說,IBM的技術非常有吸引力,因為它能夠處理不同類型的資訊,適應不同的運行環境。他關注過的一些小公司的技術只能搜索範圍要窄得多的資訊類型。
珍妮特說,同時管理結構化資料和電子郵件、文本文檔等非結構化資料代表著內容管理產業的未來。IBM的策略是開發面向大企業客戶的全功能資訊管理平臺。菲爾德曼表示,其他公司銷售的產品只能解決不太複雜的技術。
儘管IBM在關聯資料庫市場上是一家重量級廠商,但其大多數與搜索相關的工作仍然處於研發階段。維克多表示,IBM在企業搜索市場上最大的挑戰可能是其形象,而不是技術。當客戶想到搜索時,它們不會想到IBM。IBM能夠使自己被客戶接受為搜索服務提供商嗎?
2008年2月19日 星期二
Google---資源描述架構(RDF) 在都柏林核心集的應用介紹
一、前言
資源描述結構(Resource Description Framework,簡稱 RDF)是一個用來攜帶多種不同的元資料來往於網路上的工具。[註 1] 元資料(Metadata)最常見的英文定義是 "data about data",可直譯為描述資料的資料,主要是描述資料屬性的資訊,用來支持如指示儲存位置、資源尋找、文件紀錄、評價、過濾等的功能。以圖書館的角度來看,就其本義和功能而言,元資料可說是電子式目錄,因為編製目錄的目的,即在描述收藏資料的內容或特色,進而達成協助資料檢索的目的。[註 2] 因此元資料是用來揭示各類型電子文件或檔案的內容和其他特性,其典型的作業環境是電腦網路作業環境。換言之,元資料是因應現代資料處理上的二大挑戰而興起的:一是電子檔案成為資料的主流,另外一個是網路上大量文件的管理和檢索需求。
至於元資料的種類,下面是一些常見的清單。首先,國際圖書館協會聯盟(International Federation of Library Association and Institutions,簡稱 IFLA)在描述元資料資源的首頁中 [註 3],列舉了以下的元資料種類: Dublin Core、EAD(Encoded Archival Description)、FGDC's Content Standard for Digital Geospatial Metadata、DIF (Directory Interchange Format)、GILS (Government Information Locator Service)、IAFA/whois++ templates、MARC、PICS (Platform for Internet Content Selection)、RDM(Resource Description Messages)、SOIF(Summary Object Interchange Format)、SHOE(Simple HTML Ontology Extensions)、TEI、URC(Uniform Resource Characteristics)、X3L8 Proposed ANSI standard for data representation。
其次是在『Judy And Magda's List of Metadata Initiatives』的網頁中,按類別提出一些經常被廣泛使用或具有潛力的元資料如下︰ [註 4]
(一) 通用描述型 -- MARC、Dublin Core、Edinburgh Engineering Virtual Library (EEVL)、Semantic Header for Internet Documents、GILS、URC、X3L8 Proposed ANSI standard for data representation、IAFA Templates、NetFirst、Header for HTML documents、SOIF、MCF(Meta content Format)、PICS。
(二) 文字檔描述型 -- TEI、BibTex、Gruber Ontology for Bibliographic Data、RFC 1807。
(三) 數據資料類-- ICPSR Data Documentation Initiative、SDSM(Standard for Survey Design and Statistical Methodology Metadata)。
(四) 音樂類 -- SMDL(Standard Music Description Language)、
(五) 圖像與物件類 -- CDWA(Categories for the Description of Works of Art)、CIMI(Consortium for the Computer Interchange of Museum Information)、VRA Core Categories、MESL Data Dictionary。
(六) 地理資料類 -- FGDC's Content Standards for Digital Geospatial Metadata。
(七) 檔案保存類 -- EAD、Z39.50 Profile for Access to Digital Collections、Fattahi Prototype Catalogue of Super Records。
由以上的列表和清單可知,因為網路資源的種類複雜,用途殊異,因此多種元資料共存共榮實為不可避免的趨勢,因此需要有一種適當的工具,來同時攜帶多種元資料來往於網路上,而「資源描述架構」即為此種工具之一。
資源描述結構(Resource Description Framework,簡稱 RDF)是由全球資訊網協會(W3C)主導和結合多個元資料團體(如都柏林核心集等)所發展而成的一個架構,可用來攜帶多種不同的元資料來往於網際網路和WWW上。因為W3C先前曾致力發展一個元資料─PICS(Platform for Internet Content Selection) [註 5],因此RDF受到PICS很深的影響,在語法上則是遵循另一個W3C致力推廣的架構 -- XML(Extensible Markup Language)[註 6],由於目前XML已受到業界廣泛的支持,如瀏覽器的兩大霸主Netscape [註 7] 和 Internet Explorer [註 8] 都已經各自製作使用XML格式的元資料規格,並且也已呈送W3C審核,因此XML與RDF的發展可說是備受矚目。
二、RDF的核心資料模式與聲明的機制
以下根據W3C 的RDF工作小組的草案 [註 9],來對 RDF模型做更進一步的介紹,基本上RDF是一個與任何特定(電腦)語法無關的抽象的資料(表達)模式,用來呈現一個特性與其值。而所謂的「特性」(Property),可能是
資源的屬性:如題名、著者等,都柏林核心集的題名(Title)欄位即可歸屬於這類。
資源間的關係:如都柏林核心集的關連(Relation)和來源(Source)兩欄位即屬於這類範疇。
RDF的另外一個特點是語法獨立性,因此兩段看起來差異很大的RDF陳述,事實上可能是描述相同的一件事,這是因為RDF是一個抽象的資料模式。由於這個抽象的特點,各種不同的元資料(如都柏林核心集)均可利用此種抽象的資料模式,來表達它們的內容。
RDF的核心資料模式(RDF Core)定義如下:
(一) N:一個點(Node)的集合(Set),此處的「集合」是一個數學的名詞和概念,在此的意義和用法正如在數學中一般。而「點」可以是一個資源(如網頁)或是物件(Object),甚至可以是一個「特性」(Property)。[作者註:「特性」的意義請參見前面的描述。]
(二) P(特性型態):是一個 N 的子集合(Subset)。
(三) T:一個含有三個元素的「有序對」(Tuple),其形式為(P, N, V),即有序對中的第一個元素來自前面的集合 P,第二個元素來自前面的集合 N,第三個元素V可以是來自集合 N,或者是一個單純的值(如字串 ”吳政叡”)。
例子:吳政叡是網頁 http://mes.lins.fju.edu.tw 的著者,可用RDF的有序對表示如下:
{著者,[http://mes.lins.fju.edu.tw],[吳政叡]}
上述的有序對中,著者是一個「特性」,[吳政叡]是此特性的值,網頁 http://mes.lins.fju.edu.tw 是一個點(Node)。
從另外一個角度,可把RDF核心資料模式的三個元素有序對(P, N, V),以數學中的圖學表示如下:
N -- P -- > V
即將 N 和V視為點,P是從N 到V弧線的標示,因此上述的例子又可表示為
[http://mes.lins.fju.edu.tw] -- 著者 -- > [吳政叡]
此外又可透過所謂的「具體化」(Reification)將「特性」(Property)變成一個新的點(假設為 X),從而產生三個新的有序對如下:
(一) {PropName, X, P}。
(二) {PropObj, X, N}。
(三) {PropValue, X, V}。
以上面的例子來說,若將「特性」著者具體化為新的點X後,將產生如下的三個新有序對
(一) {PropName, X, 著者}。
(二) { PropObj, X, [http://mes.lins.fju.edu.tw]}。
(三) { PropValue, X, [吳政叡]}。
若將描述同一個資源的眾多特性的有序對集結起來,即成為RDF的「聲明」(Assertion),例如描述網頁 http://mes.lins.fju.edu.tw 的兩個有序對
(一) {著者,[http://mes.lins.fju.edu.tw],[吳政叡]}
(二) {題名,[http://mes.lins.fju.edu.tw],[吳政叡的首頁]}
組合起來即構成RDF的「聲明」。
三、一個都柏林核心集記錄的RDF實例
都柏林核心集(Dublin Core)為備受矚目的元資料之一,是 1995 年 3 月由國際圖書館電腦中心(Online Computer Library Center,簡稱OCLC)和 National Center for Supercomputing Applications(NCSA)所聯合贊助的研討會,經過五十二位來自圖書館、電腦和網路方面的學者和專家,共同研討下的產物。目的是希望建立一套描述網路上電子文件特色的方法,來協助資訊檢索。研討會的中心問題是--如何用一個簡單的元資料記錄來描述種類繁多的電子物件?[註 10] 主要的目標是發展一個簡單有彈性,且非圖書館專業人員也可輕易了解和使用的資料描述格式,來描述網路上的電子文件。
都柏林核心集最近一次的研討會為第五次研討會,於1997年10月6-8日在芬蘭的赫爾辛基舉行,由於在寫作本書時,第五次研討會的正式報告尚未出版,祇好先根據澳洲國家圖書館的一位與會者--Bemal Rajapatirana的報告先行介紹第五次研討會的情況與成果 [註11],待第五次研討會的正式報告出爐後,作者會另撰專文來加以介紹。
根據Bemal Rajapatirana的報告,與會者達成了如下的幾項共識:
(一) 加快標準化的腳步—由於都柏林核心集的15個基本項目架構,自第四次研討會以來已普遍獲得認同,同時都柏林核心集也得到世界各國很多研究者的肯定,並且嘗試建造系統,此時若無一定的標準來遵循,將使系統的建造者無所適從和系統的更改頻繁。因此基於都柏林核心集已趨成熟的共識,決定推派代表撰寫RFC的草案,呈交給 IETF進行標準化的過程。
(二) 區分簡單和複雜兩種都柏林核心集格式—簡言之,所謂簡單(simple)和複雜(complex)格式的區分,一般而言主要是以有無使用任何修飾詞作為標準來劃分的。由於都柏林核心集的15個基本項目已有共識,因此簡單都柏林核心集的標準化過程將會較早開始。
(三) 語法上採用HTML和RDF格式為主—HTML的格式目前是使用4.0版本,寫法請參見作者的另一篇文章 [註 12]。
(四) 成立工作小組—針對一些尚未有定論的議題,組成工作小組進行研討,主要有
(1) 內容或格式尚未有定論的基本項目,如Date、Relation、Rights Management等項目。
(2) 修飾詞。
(3) 特殊性議題,如都柏林核心集和Z39.50間的互換。
(五) 次項目(或類別修飾詞)的制定原則
(1) 與基本項目一致,都是可省略的選擇項。
(2) 次項目須能進一步協助詮釋項目的內容。
(3) 祇展開一層,免得結構過於複雜。
(4) 數目盡可能精簡,有可能需要類別修飾詞的基本項目,將限於Title、Creator、Contributor、Publisher、Date、Relation、Coverage等。
1997年10月公布的資料著錄項目列表如下:[註13]
(一) 主題和關鍵詞(Subject):作品所屬的學術領域,控制語彙用 scheme 註明出處如 LCSH,亦可包含分類號如杜威十進分類號(Dewey Decimal Number)。
例子:Subject = 都柏林核心集。
(二) 題名(Title):作品名稱。
例子:Title = 都柏林核心集與元資料實驗系統。
(三) 著者(Creator):作品的創作者或組織。
例子:Creator = 吳政叡。
(四) 簡述(Description):文件的摘要或影像資源的內容敘述。
(五) 出版者(Publisher):負責發行作品的組織。
(六) 其他參與者(Contributors):除了著者外,對作品創作有貢獻的其他相關人士或組織。
〔註: 如書中插圖的製作者。〕
(七) 出版日期(Date):作品公開發表的日期,建議使用如下格式– YYYY-MM-DD和參考下列網址:http://www.w3.org/TR/NOTE-datetime。在此網頁中共規範有六種格式,都是根據國際標準日期暨時間格式 – ISO(國際標準組織)8601制定而成,是ISO 8601的子集合(subset),現在列舉和解說如下以供參考:[註 14]
例子:1997-09-07(西元1997年9月7日)。
(八) 資源類型(Type):作品的類型或所屬的抽象範疇,例如網頁、小說、詩、技術報告、字典等,建議參考下列網址:http://sunsite.berkeley.edu/Metadata/types.html。
例子:Type = Text.Dictionary。
例子:Type = 文字.技術報告。
(九) 資料格式(Format):告知檢索者在使用此作品時,所須的電腦軟體和硬體設備,例如 text/html(MIME格式)、ASCII、Postscript(一種印表機通用格式)、可執行程式、JPEG(一種通用圖像格式)。亦可擴展至非電子文件,例如book(書本)、叢書、期刊。
例子:Format = text/html。
(十) 資源識別代號(Identifier):字串或號碼可用來唯一標示此作品,例如URN、URL、ISSN、ISBN等。
(十一) 關連(Relation):與其他作品(不同內容範疇)的關連,或所屬的系列和檔案庫。
例子:Relation = http://mes.lins.fju.edu.tw/。
(十二) 來源(Source):作品從何處衍生而來(同內容範疇),例如莎士比亞的某個電子書出自那個紙本。
(十三) 語言(Language):作品所使用的語言,建議遵循 RFC 1766 的規定,請參考下列網址:http://ds.internic.net/rfc/rfc1766.txt,RFC 1766 是使用 ISO 639的二個字母的語言代碼。[註 15]
例子:Language = en。[註16]
(十四) 涵蓋時空(Coverage):作品所涵蓋的時期和地理區域。
(十五) 版權規範(Rights):作品版權聲明和使用規範。
以下是使用 XML語法和 RDF核心資料模式來攜帶一個都柏林核心集記錄的實例:
< xml::namespace href="http://www.w3.org/schemas/rdf-schema" as="RDF">
吳政叡
元資料實驗系統
都柏林核心集
元資料
有鑒於元資料對資料著錄和檢索的重要性,作者建立了一個相關的實驗系統—元資料實驗系統 (Metadata Experimental System,簡稱MES,網址: http://140.136.85.194/mes 或 http://mes.lins.fju.edu.tw/mes),作者建立MES目的,除了是讓讀者透過這個系統,對元資料及其未來的可能運作方式,有更具體的認知外;也希望利用此一實驗系統,來測試和驗證元資料的功能和效用,例如都柏林核心集這種簡易的資料描述格式,是否如制定者們所預期的,足以滿足大部分網路文件著錄和檢索的需求。MES是一開放性的實驗系統,歡迎任何人上站著錄自己的網頁或文件,以供他人查詢和檢索。
1997-009
homepage
text/html
http://140.136.85.194/mes
所有版權屬於吳政叡
下面的RDF文法是摘錄自W3C 的RDF工作小組 1997年10月2日公開的草案 [註 17],此文法是以電腦界通用的BNF(Backus-Naur Form)[註 18] 形式呈現,同時由於工作小組的草案是會隨時增修的,請自行連上W3C 的網站(http://www.w3.org/Metadata/RDF/Group/WD-rdf-syntax)查看最新的發展。
(一) RDF ::= ' ' node* ' '
(二) node ::= resource | assertions | aggregate
(三) resource ::= '' property* ''
(四) assertions ::= '' property* ''
(五) aggregate ::= sequence | bag | alternatives
(六) sequence ::= '' aggnode* ''
(七) bag ::= '' aggnode* ''
(八) alternatives ::= '' aggnode* ''
(九) aggnode ::= node | '
(十) idRefAttr ::= hrefAttr | idAttr
(十一) hrefAttr ::= 'href="' resourceURI '"'
(十二) idAttr ::= 'id="' IDsymbol '"'
(十三) resourceURI ::= (see RFC1738)
(十四) IDsymbol ::= (any legal XML name symbol)
(十五) property ::= '<' propName idAttr? '>' propValue '' | '<' propName idRefAttr '/>'
(十六) propName ::= name | namePrefix ':' name
(十七) propValue ::= node | string
(十八) name ::= (any legal XML name symbol)
(十九) namePrefix ::= (any legal XML namespace prefix)
(二十) string ::= (any XML text)
四、結語
元資料的興起和WWW與搜尋引擎的盛行頗有關連,WWW盛行後,為因應檢索網頁內容的需要而有搜尋引擎的產生,搜尋引擎運作的方式,基本上是屬於全文檢索,主要是透過自動抓取程式在網際網路上抓取網頁,然後以自動拆字(或詞)作索引的方式來建立其資料庫,做為檢索的基礎,這種操作方式的特點是高運作效率和一網打盡,因此有高回收率與低精確率的特性,這個低精確率的缺點,隨著WWW網頁數量的急遽膨脹,成為無法忍受的致命傷。
很明顯的,我們需要更多的資訊,來從回覆的款目當中,挑選我們真正需要的資料,而這些資訊必須由資料提供者來提供,因此如何制定一套資料描述格式,來有效率的描述收藏的資料,成為一個重要的課題,這正是元資料日漸受到重視的原因。這種對資料須加以適當描述的體會,正是圖書館製作目錄的動機,於是這個古老的經驗又得到再一次的肯定。
都柏林核心集(Dublin Core)是一個簡單有彈性,且非圖書館專業人員也可輕易了解和使用的資料描述格式。這種簡單有彈性和適合各種專業人員的特性,正是它在國外越來越受到歡迎的主要因素,也是作者特別青睞都柏林核心集的原因,這是因為作者同時具有圖書館學和電腦的背景,了解到在現階段,一種適合各專業人士的簡易元資料的必要性;一方面傳統的機讀編目格式過於繁瑣,也繼承太多的傳統包袱,同時傳統圖書館的著錄方式並不適合非圖書館專業的人。另一方面以作者對目前人工智慧、類神經元網路、模糊邏輯等相關學科的了解,知道創造一個具有現今一般圖書館員智慧的自動化系統,在現階段仍是一個遙不可及的夢想,因為至今我們連模仿一個三歲小孩說和聽故事的智力都有困難,更別說是模仿一個成年的專業人士。所以綜合來說,在現階段資料的描述仍需以人工作業為主,同時以今日網際網路上資料膨脹的速度來看,光靠圖書館員來處理是不夠的,由(眾多專業的)文件或資料的創造者本身來自行加以描述,已是必然的趨勢,這正是類似都柏林核心集這種元資料受重視的原因。
以都柏林核心集在國外的發展現況來看,1997年10月的第五次研討會已有專門的議程來針對都柏林核心集的實作系統進行展示和討論,這是以前四次研討會所沒有的,也說明都柏林核心集已漸趨成熟和受到肯定。除了已開發系統的介紹外,也有一些正在籌建中的都柏林核心集相關系統的宣佈,以下是它們的簡介:
(一) 丹麥政府決定自西元1997年起將所有政府的出版物上網,系統的主要規格之一,是採用都柏林核心集來描述文件和協助查詢。
(二) 荷蘭國家圖書館將發展一種新的全球資訊網服務,系統的主要做法是要在所有已蒐集的網頁中,加入都柏林核心集的資料,新的網頁將要求提供者先自行加入都柏林核心集的資料後再送呈,將來荷蘭國家圖書館的搜尋引擎會利用這些元資料來協助檢索。
(三) 英國的UKOLN正在推行一個名為BIBLINK的計劃,在出版社和國家書目中心間建立一條網路通訊管道,來直接交換書籍紀錄和資訊,這套系統是使用都柏林核心集作為其基本的格式。
(四) 在商業的應用上,一個稱為STARTS的協定正在發展中,它可以辨識網頁中的元資料,來協助使用者過濾和排比查詢的結果,STARTS已決定包含都柏林核心集。
綜觀以上的發展,顯示都柏林核心集已漸成熟和廣受肯定,以系統的實作而言,歐洲和澳洲(請參見下面第四章中關於DSTC的介紹)可說是居於領先的地位,歐洲較注重都柏林核心集在圖書館相關服務上的應用,澳洲的DSTC則較偏重都柏林核心集在WWW相關服務上的應用。
由於類似都柏林核心集這類的元資料正逐漸獲得肯定和使用,因此相關的攜帶工具也成為研究者注目的焦點。這是因為元資料的種類複雜且用途殊異,將來多種元資料共存共榮的局面已成為共識,因此一種可同時攜帶多種元資料來往於網際網路和WWW上的架構,成為不可或缺的工具。基於此種認知,W3C乃主導和結合多個元資料團體發展出「資源描述架構」(RDF)。雖然在第二次都柏林核心集的研討會中,也提出一個類似的多個元資料的攜帶工具─「瓦立克架構」[註 19],但是由於W3C在網際網路和WWW界的影響力甚鉅,作者預期RDF終將獲得採用而取代「瓦立克架構」,成為攜帶都柏林核心集的主要工具,因此撰寫本文來介紹資源描述架構在都柏林核心集的可能應用方式。
分享至PLURK 噗浪
分享至FACEBOOK 臉書
資源描述結構(Resource Description Framework,簡稱 RDF)是一個用來攜帶多種不同的元資料來往於網路上的工具。[註 1] 元資料(Metadata)最常見的英文定義是 "data about data",可直譯為描述資料的資料,主要是描述資料屬性的資訊,用來支持如指示儲存位置、資源尋找、文件紀錄、評價、過濾等的功能。以圖書館的角度來看,就其本義和功能而言,元資料可說是電子式目錄,因為編製目錄的目的,即在描述收藏資料的內容或特色,進而達成協助資料檢索的目的。[註 2] 因此元資料是用來揭示各類型電子文件或檔案的內容和其他特性,其典型的作業環境是電腦網路作業環境。換言之,元資料是因應現代資料處理上的二大挑戰而興起的:一是電子檔案成為資料的主流,另外一個是網路上大量文件的管理和檢索需求。
至於元資料的種類,下面是一些常見的清單。首先,國際圖書館協會聯盟(International Federation of Library Association and Institutions,簡稱 IFLA)在描述元資料資源的首頁中 [註 3],列舉了以下的元資料種類: Dublin Core、EAD(Encoded Archival Description)、FGDC's Content Standard for Digital Geospatial Metadata、DIF (Directory Interchange Format)、GILS (Government Information Locator Service)、IAFA/whois++ templates、MARC、PICS (Platform for Internet Content Selection)、RDM(Resource Description Messages)、SOIF(Summary Object Interchange Format)、SHOE(Simple HTML Ontology Extensions)、TEI、URC(Uniform Resource Characteristics)、X3L8 Proposed ANSI standard for data representation。
其次是在『Judy And Magda's List of Metadata Initiatives』的網頁中,按類別提出一些經常被廣泛使用或具有潛力的元資料如下︰ [註 4]
(一) 通用描述型 -- MARC、Dublin Core、Edinburgh Engineering Virtual Library (EEVL)、Semantic Header for Internet Documents、GILS、URC、X3L8 Proposed ANSI standard for data representation、IAFA Templates、NetFirst、Header for HTML documents、SOIF、MCF(Meta content Format)、PICS。
(二) 文字檔描述型 -- TEI、BibTex、Gruber Ontology for Bibliographic Data、RFC 1807。
(三) 數據資料類-- ICPSR Data Documentation Initiative、SDSM(Standard for Survey Design and Statistical Methodology Metadata)。
(四) 音樂類 -- SMDL(Standard Music Description Language)、
(五) 圖像與物件類 -- CDWA(Categories for the Description of Works of Art)、CIMI(Consortium for the Computer Interchange of Museum Information)、VRA Core Categories、MESL Data Dictionary。
(六) 地理資料類 -- FGDC's Content Standards for Digital Geospatial Metadata。
(七) 檔案保存類 -- EAD、Z39.50 Profile for Access to Digital Collections、Fattahi Prototype Catalogue of Super Records。
由以上的列表和清單可知,因為網路資源的種類複雜,用途殊異,因此多種元資料共存共榮實為不可避免的趨勢,因此需要有一種適當的工具,來同時攜帶多種元資料來往於網路上,而「資源描述架構」即為此種工具之一。
資源描述結構(Resource Description Framework,簡稱 RDF)是由全球資訊網協會(W3C)主導和結合多個元資料團體(如都柏林核心集等)所發展而成的一個架構,可用來攜帶多種不同的元資料來往於網際網路和WWW上。因為W3C先前曾致力發展一個元資料─PICS(Platform for Internet Content Selection) [註 5],因此RDF受到PICS很深的影響,在語法上則是遵循另一個W3C致力推廣的架構 -- XML(Extensible Markup Language)[註 6],由於目前XML已受到業界廣泛的支持,如瀏覽器的兩大霸主Netscape [註 7] 和 Internet Explorer [註 8] 都已經各自製作使用XML格式的元資料規格,並且也已呈送W3C審核,因此XML與RDF的發展可說是備受矚目。
二、RDF的核心資料模式與聲明的機制
以下根據W3C 的RDF工作小組的草案 [註 9],來對 RDF模型做更進一步的介紹,基本上RDF是一個與任何特定(電腦)語法無關的抽象的資料(表達)模式,用來呈現一個特性與其值。而所謂的「特性」(Property),可能是
資源的屬性:如題名、著者等,都柏林核心集的題名(Title)欄位即可歸屬於這類。
資源間的關係:如都柏林核心集的關連(Relation)和來源(Source)兩欄位即屬於這類範疇。
RDF的另外一個特點是語法獨立性,因此兩段看起來差異很大的RDF陳述,事實上可能是描述相同的一件事,這是因為RDF是一個抽象的資料模式。由於這個抽象的特點,各種不同的元資料(如都柏林核心集)均可利用此種抽象的資料模式,來表達它們的內容。
RDF的核心資料模式(RDF Core)定義如下:
(一) N:一個點(Node)的集合(Set),此處的「集合」是一個數學的名詞和概念,在此的意義和用法正如在數學中一般。而「點」可以是一個資源(如網頁)或是物件(Object),甚至可以是一個「特性」(Property)。[作者註:「特性」的意義請參見前面的描述。]
(二) P(特性型態):是一個 N 的子集合(Subset)。
(三) T:一個含有三個元素的「有序對」(Tuple),其形式為(P, N, V),即有序對中的第一個元素來自前面的集合 P,第二個元素來自前面的集合 N,第三個元素V可以是來自集合 N,或者是一個單純的值(如字串 ”吳政叡”)。
例子:吳政叡是網頁 http://mes.lins.fju.edu.tw 的著者,可用RDF的有序對表示如下:
{著者,[http://mes.lins.fju.edu.tw],[吳政叡]}
上述的有序對中,著者是一個「特性」,[吳政叡]是此特性的值,網頁 http://mes.lins.fju.edu.tw 是一個點(Node)。
從另外一個角度,可把RDF核心資料模式的三個元素有序對(P, N, V),以數學中的圖學表示如下:
N -- P -- > V
即將 N 和V視為點,P是從N 到V弧線的標示,因此上述的例子又可表示為
[http://mes.lins.fju.edu.tw] -- 著者 -- > [吳政叡]
此外又可透過所謂的「具體化」(Reification)將「特性」(Property)變成一個新的點(假設為 X),從而產生三個新的有序對如下:
(一) {PropName, X, P}。
(二) {PropObj, X, N}。
(三) {PropValue, X, V}。
以上面的例子來說,若將「特性」著者具體化為新的點X後,將產生如下的三個新有序對
(一) {PropName, X, 著者}。
(二) { PropObj, X, [http://mes.lins.fju.edu.tw]}。
(三) { PropValue, X, [吳政叡]}。
若將描述同一個資源的眾多特性的有序對集結起來,即成為RDF的「聲明」(Assertion),例如描述網頁 http://mes.lins.fju.edu.tw 的兩個有序對
(一) {著者,[http://mes.lins.fju.edu.tw],[吳政叡]}
(二) {題名,[http://mes.lins.fju.edu.tw],[吳政叡的首頁]}
組合起來即構成RDF的「聲明」。
三、一個都柏林核心集記錄的RDF實例
都柏林核心集(Dublin Core)為備受矚目的元資料之一,是 1995 年 3 月由國際圖書館電腦中心(Online Computer Library Center,簡稱OCLC)和 National Center for Supercomputing Applications(NCSA)所聯合贊助的研討會,經過五十二位來自圖書館、電腦和網路方面的學者和專家,共同研討下的產物。目的是希望建立一套描述網路上電子文件特色的方法,來協助資訊檢索。研討會的中心問題是--如何用一個簡單的元資料記錄來描述種類繁多的電子物件?[註 10] 主要的目標是發展一個簡單有彈性,且非圖書館專業人員也可輕易了解和使用的資料描述格式,來描述網路上的電子文件。
都柏林核心集最近一次的研討會為第五次研討會,於1997年10月6-8日在芬蘭的赫爾辛基舉行,由於在寫作本書時,第五次研討會的正式報告尚未出版,祇好先根據澳洲國家圖書館的一位與會者--Bemal Rajapatirana的報告先行介紹第五次研討會的情況與成果 [註11],待第五次研討會的正式報告出爐後,作者會另撰專文來加以介紹。
根據Bemal Rajapatirana的報告,與會者達成了如下的幾項共識:
(一) 加快標準化的腳步—由於都柏林核心集的15個基本項目架構,自第四次研討會以來已普遍獲得認同,同時都柏林核心集也得到世界各國很多研究者的肯定,並且嘗試建造系統,此時若無一定的標準來遵循,將使系統的建造者無所適從和系統的更改頻繁。因此基於都柏林核心集已趨成熟的共識,決定推派代表撰寫RFC的草案,呈交給 IETF進行標準化的過程。
(二) 區分簡單和複雜兩種都柏林核心集格式—簡言之,所謂簡單(simple)和複雜(complex)格式的區分,一般而言主要是以有無使用任何修飾詞作為標準來劃分的。由於都柏林核心集的15個基本項目已有共識,因此簡單都柏林核心集的標準化過程將會較早開始。
(三) 語法上採用HTML和RDF格式為主—HTML的格式目前是使用4.0版本,寫法請參見作者的另一篇文章 [註 12]。
(四) 成立工作小組—針對一些尚未有定論的議題,組成工作小組進行研討,主要有
(1) 內容或格式尚未有定論的基本項目,如Date、Relation、Rights Management等項目。
(2) 修飾詞。
(3) 特殊性議題,如都柏林核心集和Z39.50間的互換。
(五) 次項目(或類別修飾詞)的制定原則
(1) 與基本項目一致,都是可省略的選擇項。
(2) 次項目須能進一步協助詮釋項目的內容。
(3) 祇展開一層,免得結構過於複雜。
(4) 數目盡可能精簡,有可能需要類別修飾詞的基本項目,將限於Title、Creator、Contributor、Publisher、Date、Relation、Coverage等。
1997年10月公布的資料著錄項目列表如下:[註13]
(一) 主題和關鍵詞(Subject):作品所屬的學術領域,控制語彙用 scheme 註明出處如 LCSH,亦可包含分類號如杜威十進分類號(Dewey Decimal Number)。
例子:Subject = 都柏林核心集。
(二) 題名(Title):作品名稱。
例子:Title = 都柏林核心集與元資料實驗系統。
(三) 著者(Creator):作品的創作者或組織。
例子:Creator = 吳政叡。
(四) 簡述(Description):文件的摘要或影像資源的內容敘述。
(五) 出版者(Publisher):負責發行作品的組織。
(六) 其他參與者(Contributors):除了著者外,對作品創作有貢獻的其他相關人士或組織。
〔註: 如書中插圖的製作者。〕
(七) 出版日期(Date):作品公開發表的日期,建議使用如下格式– YYYY-MM-DD和參考下列網址:http://www.w3.org/TR/NOTE-datetime。在此網頁中共規範有六種格式,都是根據國際標準日期暨時間格式 – ISO(國際標準組織)8601制定而成,是ISO 8601的子集合(subset),現在列舉和解說如下以供參考:[註 14]
例子:1997-09-07(西元1997年9月7日)。
(八) 資源類型(Type):作品的類型或所屬的抽象範疇,例如網頁、小說、詩、技術報告、字典等,建議參考下列網址:http://sunsite.berkeley.edu/Metadata/types.html。
例子:Type = Text.Dictionary。
例子:Type = 文字.技術報告。
(九) 資料格式(Format):告知檢索者在使用此作品時,所須的電腦軟體和硬體設備,例如 text/html(MIME格式)、ASCII、Postscript(一種印表機通用格式)、可執行程式、JPEG(一種通用圖像格式)。亦可擴展至非電子文件,例如book(書本)、叢書、期刊。
例子:Format = text/html。
(十) 資源識別代號(Identifier):字串或號碼可用來唯一標示此作品,例如URN、URL、ISSN、ISBN等。
(十一) 關連(Relation):與其他作品(不同內容範疇)的關連,或所屬的系列和檔案庫。
例子:Relation = http://mes.lins.fju.edu.tw/。
(十二) 來源(Source):作品從何處衍生而來(同內容範疇),例如莎士比亞的某個電子書出自那個紙本。
(十三) 語言(Language):作品所使用的語言,建議遵循 RFC 1766 的規定,請參考下列網址:http://ds.internic.net/rfc/rfc1766.txt,RFC 1766 是使用 ISO 639的二個字母的語言代碼。[註 15]
例子:Language = en。[註16]
(十四) 涵蓋時空(Coverage):作品所涵蓋的時期和地理區域。
(十五) 版權規範(Rights):作品版權聲明和使用規範。
以下是使用 XML語法和 RDF核心資料模式來攜帶一個都柏林核心集記錄的實例:
< xml::namespace href="http://www.w3.org/schemas/rdf-schema" as="RDF">
下面的RDF文法是摘錄自W3C 的RDF工作小組 1997年10月2日公開的草案 [註 17],此文法是以電腦界通用的BNF(Backus-Naur Form)[註 18] 形式呈現,同時由於工作小組的草案是會隨時增修的,請自行連上W3C 的網站(http://www.w3.org/Metadata/RDF/Group/WD-rdf-syntax)查看最新的發展。
(一) RDF ::= '
(二) node ::= resource | assertions | aggregate
(三) resource ::= '
(四) assertions ::= '
(五) aggregate ::= sequence | bag | alternatives
(六) sequence ::= '
(七) bag ::= '
(八) alternatives ::= '
(九) aggnode ::= node | '
(十) idRefAttr ::= hrefAttr | idAttr
(十一) hrefAttr ::= 'href="' resourceURI '"'
(十二) idAttr ::= 'id="' IDsymbol '"'
(十三) resourceURI ::= (see RFC1738)
(十四) IDsymbol ::= (any legal XML name symbol)
(十五) property ::= '<' propName idAttr? '>' propValue '' | '<' propName idRefAttr '/>'
(十六) propName ::= name | namePrefix ':' name
(十七) propValue ::= node | string
(十八) name ::= (any legal XML name symbol)
(十九) namePrefix ::= (any legal XML namespace prefix)
(二十) string ::= (any XML text)
四、結語
元資料的興起和WWW與搜尋引擎的盛行頗有關連,WWW盛行後,為因應檢索網頁內容的需要而有搜尋引擎的產生,搜尋引擎運作的方式,基本上是屬於全文檢索,主要是透過自動抓取程式在網際網路上抓取網頁,然後以自動拆字(或詞)作索引的方式來建立其資料庫,做為檢索的基礎,這種操作方式的特點是高運作效率和一網打盡,因此有高回收率與低精確率的特性,這個低精確率的缺點,隨著WWW網頁數量的急遽膨脹,成為無法忍受的致命傷。
很明顯的,我們需要更多的資訊,來從回覆的款目當中,挑選我們真正需要的資料,而這些資訊必須由資料提供者來提供,因此如何制定一套資料描述格式,來有效率的描述收藏的資料,成為一個重要的課題,這正是元資料日漸受到重視的原因。這種對資料須加以適當描述的體會,正是圖書館製作目錄的動機,於是這個古老的經驗又得到再一次的肯定。
都柏林核心集(Dublin Core)是一個簡單有彈性,且非圖書館專業人員也可輕易了解和使用的資料描述格式。這種簡單有彈性和適合各種專業人員的特性,正是它在國外越來越受到歡迎的主要因素,也是作者特別青睞都柏林核心集的原因,這是因為作者同時具有圖書館學和電腦的背景,了解到在現階段,一種適合各專業人士的簡易元資料的必要性;一方面傳統的機讀編目格式過於繁瑣,也繼承太多的傳統包袱,同時傳統圖書館的著錄方式並不適合非圖書館專業的人。另一方面以作者對目前人工智慧、類神經元網路、模糊邏輯等相關學科的了解,知道創造一個具有現今一般圖書館員智慧的自動化系統,在現階段仍是一個遙不可及的夢想,因為至今我們連模仿一個三歲小孩說和聽故事的智力都有困難,更別說是模仿一個成年的專業人士。所以綜合來說,在現階段資料的描述仍需以人工作業為主,同時以今日網際網路上資料膨脹的速度來看,光靠圖書館員來處理是不夠的,由(眾多專業的)文件或資料的創造者本身來自行加以描述,已是必然的趨勢,這正是類似都柏林核心集這種元資料受重視的原因。
以都柏林核心集在國外的發展現況來看,1997年10月的第五次研討會已有專門的議程來針對都柏林核心集的實作系統進行展示和討論,這是以前四次研討會所沒有的,也說明都柏林核心集已漸趨成熟和受到肯定。除了已開發系統的介紹外,也有一些正在籌建中的都柏林核心集相關系統的宣佈,以下是它們的簡介:
(一) 丹麥政府決定自西元1997年起將所有政府的出版物上網,系統的主要規格之一,是採用都柏林核心集來描述文件和協助查詢。
(二) 荷蘭國家圖書館將發展一種新的全球資訊網服務,系統的主要做法是要在所有已蒐集的網頁中,加入都柏林核心集的資料,新的網頁將要求提供者先自行加入都柏林核心集的資料後再送呈,將來荷蘭國家圖書館的搜尋引擎會利用這些元資料來協助檢索。
(三) 英國的UKOLN正在推行一個名為BIBLINK的計劃,在出版社和國家書目中心間建立一條網路通訊管道,來直接交換書籍紀錄和資訊,這套系統是使用都柏林核心集作為其基本的格式。
(四) 在商業的應用上,一個稱為STARTS的協定正在發展中,它可以辨識網頁中的元資料,來協助使用者過濾和排比查詢的結果,STARTS已決定包含都柏林核心集。
綜觀以上的發展,顯示都柏林核心集已漸成熟和廣受肯定,以系統的實作而言,歐洲和澳洲(請參見下面第四章中關於DSTC的介紹)可說是居於領先的地位,歐洲較注重都柏林核心集在圖書館相關服務上的應用,澳洲的DSTC則較偏重都柏林核心集在WWW相關服務上的應用。
由於類似都柏林核心集這類的元資料正逐漸獲得肯定和使用,因此相關的攜帶工具也成為研究者注目的焦點。這是因為元資料的種類複雜且用途殊異,將來多種元資料共存共榮的局面已成為共識,因此一種可同時攜帶多種元資料來往於網際網路和WWW上的架構,成為不可或缺的工具。基於此種認知,W3C乃主導和結合多個元資料團體發展出「資源描述架構」(RDF)。雖然在第二次都柏林核心集的研討會中,也提出一個類似的多個元資料的攜帶工具─「瓦立克架構」[註 19],但是由於W3C在網際網路和WWW界的影響力甚鉅,作者預期RDF終將獲得採用而取代「瓦立克架構」,成為攜帶都柏林核心集的主要工具,因此撰寫本文來介紹資源描述架構在都柏林核心集的可能應用方式。
Google如何靠語義網擊敗EBAY和AMAZON?
August 2009: How Google beat Amazon and Ebay to the Semantic Web
July 26, 2002 By Paul Ford
一個虛構的故事,關於語義網的劇本。2009 年商業雜誌上的短篇特寫。請注意這篇文章是2002年寫的。
這真讓人難以置信,Google(現在世界上最大的獨立在線交易市場) 在僅僅8年多一點的時間就登上了舞台, 過去那可是Amazon和Ebay的統治領域。怎麼Google 就成為了世界上最大的獨立在線交易市場呢?
很好,簡而言之,答案就是「語義網」(一會兒我再告訴你這是什麼)。當Amazon和Ebay各自繼續以每季贏利10億和18億美元的時候,任何人都認為這是成功的,但Google在網絡交易市場每年盈利170億美元則被認定是更加成功的故事,前所未有的——「新經濟」。
Amazon和Ebay都努力開發虛擬交易市場:他們盡可能地外包庫存。然後,通過各種各樣的方法,把買主和賣主吸引到同一件商品上,從交易中抽取利潤。
對於Amazon來說,那意味著售賣新(商品)項目,或者允許眾多用戶賣出他們使用過的商品。對Ebay而言,它意味著把招標人和買主吸引在一起。一旦你被吸引進來, 這種途徑是極其有利潤的,它還是快速的,通過電話、電子郵件和數據庫管理。這很有效。
再來看看Google。在2002 年以前, 它是一個搜索引擎,依靠其廣告盈利。與此同時, 自1998年以來,「語義網」的理念獲得了少數人的關注,並吸引了與日俱增的這個圈子的人們。
什麼是語義網呢? 在其心臟部分, 這僅僅是一個以計算機能理解的方法來描述事物的;當然,它並不理解這是怎麼一回事,而是邏輯,就像在高中學的:
如果A是B的朋友, 那麼B就是A的朋友。
吉姆有一個朋友叫保羅。
所以,保羅有一個朋友叫吉姆。
使用的標記語言叫做RDF (在這兒是首字母的縮略, 因此你不妨學會它——它代表資源描述框架規範Resource Description Framework), 你可以把這樣的邏輯語句放到互聯網上,「網絡爬蟲」就能收集它們,並且語句能被搜索、分析、處理。它與正常搜索不同之處是, 語句可能被結合起來。所以,如果我在吉姆的站點上看到一句話「吉姆是保羅的朋友」,這時有人搜索了「保羅的朋友們」,即使保羅的網站沒有提到吉姆, 我們也會得知吉姆認為自己是保羅的朋友。
我們肯定也想知道其它的事情?比如A和B都是汽車賣主,但A賣的Miatas車比B要便宜百分之十。比如Jan Hammer 70 年代在Mahavishnu Orchestra專輯中使用的keyboards樂器。比如狗有爪子。比如你要求一台特殊型號的電腦,擁有新的主板和更快的總線,可以被升級到奔騰18。語義萬維網不是關於頁面和鏈接的, 它是考慮事物之間聯繫的——是否一件事是另一件事的一部分, 或者東西多少錢, 或什麼時候發生。
語義網最初只是作為Web缺乏「聰明」的補充——並且許多早期工作就像是安排日程和計劃, 和表述人與人之間的關係。在2003年末以前, 當Google 開始在語義網開發上作了一系列實驗的時候 (二年以後進入了他們的研究實驗室),這仍然幾乎是沒有人瞭解,並且很少人經常使用的東西, 除了在邏輯、計算機科學、人工智能方面有基礎知識的研究員。科研曲線象峭壁一樣陡, 並且對於編程人員來說,並沒有足夠的刺激來值得攀登它,也沒有從新的優勢中來研究世界的吸引力。
未來被描述的語義網,會使你更加容易預定牙醫的時間, 更新你的計算機, 檢查培訓計劃, 和協調汽車零件的發貨(時間)。它會使尋找東西更加容易。或許包括所有巨大的東西,巨大到以百萬美元起價。但不敢肯定對習慣於寫支票的人是否有足夠的誘惑, 特別是在他們經歷了95次的.com破產之後。他們看見的所有都是Web——(使他們損失了)幾個口袋和幾百萬的金錢——只不過有個「語義」在它前面修飾罷了。
Semantics vs. Syntax, Fight at 9
一件事物的語義與它的意義相關。它是一個很是模糊的東西,但是在人工智能的世界裡,這個目標將會是從句法中得出語義。至關重要的問題在於,如果你有一大堆東西整齊的按照句法規則排列成能為計算機所識別的結構,你又怎麼能從中得到意義呢?句法學如何成為語義學?人腦對此非常在行,但是對於計算機來說則是困難異常。他們對於句法感到頭疼。只要你用結構化的表達方式,就可以告訴他們任何事情,但是他們卻無法得到意義。他們會將「身有餘而心不足」這句話翻譯成「肉裡面充滿了星星但是伏特加酒是用粉紅色的羽毛做成」,像俄語一樣。
所以人們猜想,只有從句法合理的語句中才能得到真正令人感興趣的東西。實際上,你需要的是一個價值連城的腦袋。現在沒有人能證明這種方式的有效,而它的倡導者則是CYC公司的一個名叫Doug Lenat的人,他早就上了Ashcroft主席的黑名單,被視為一個危險的知識分子,已經好久沒有他的影子了。但是這些關於語義網的基本卻令人深思的概念,直到現在仍然有著影響,即通過從多個人那裡同時獲得句法,進而在他們的集合中獲得意義。
正如你所知道的,電腦仍然在聽我們的話。但是當語義網技術成熟發展起來以後,這些中心化的數據庫——例如Amazon和Ebay,他們都是有著眾多子條目的中心化數據庫–將會散落到網絡的每一處。每個人都將會有自己的那一份數據庫,他們自己的迷宮。發佈這些數據很容易,但是問題在於如何將他們聚合在一起。即使對於一些程序員來說,創建一份RDF文件也是很困難的。
這些都將會逐漸的改變,到了2004年的,Google將會有三種服務:Google市場搜索,Google個人代理和Google認證經理,以及一個軟件:Google市場經理。
Google的市場交易搜索
市場搜索位於Google語義搜索特徵的最重要的部分,而且差不多每一個瀏覽它的人至少會使用一次。你僅僅需要簡單地鍵入:
出售:「馬丁」牌吉他
來看看想買馬丁牌吉他的人的名單
購買:「馬丁」牌吉他
這是用來察看賣方的名單。
Google要求並且記得:你的郵編、按照價格組織的吉他名單中使用簡單的排序控制、狀態、型號、新的還是用過的,以及接近(的價格)。頁面是由Google的「傳統」非語義Web搜尋工具產生的,考慮在Web上長期最佳的匹配,並鏈接到馬丁型號和買者嚮導的信息,以及Google用戶新聞組的文章。還會鏈接到Epinions這樣的站點以彌補紕漏。
因此Google 市場搜索在哪裡得到信息呢?Google是以相同的方式找到它所需要的信息的——通過爬遍它找到的所有網絡和索引。而現在,它正尋找RDDL文件,它會指向RDF 文件,包含這樣的邏輯語句:
(Scott Rahin)住址的郵政編碼 (11231)
(Scott Rahin)電子郵箱地址(ford@ftrain.com)
(Scott Rahin)擁有(馬丁吉他)
[Scott的](馬丁吉他)型號是(245)。
[Scott的](馬丁吉他)可以在(http://ftrain.com/picture/martin.jpg)這裡看見
[Scott的](馬丁吉他)價值(900美元)
[Scott的](馬丁吉他)狀況(良好)
[Scott的](馬丁吉他)可以被描述成「保存得很好,並且很少玩(傷心啊!)。美妙,圓潤的聲音和一套多餘的吉他弦。我很高興能向順便拜訪的人展示它,或者在紐約市內的任何地方交付它」。
理解上面語句最重要的部分不只是在方括號和圓括號之間,而是指針。(Scott Rahin)是指向http://ftrain.com/people/Scott的一個指針。(馬丁牌原聲吉他)是指向URL的指針,它會反向參考包含其他邏輯語句的專業知識數據庫,像這樣:
(馬丁吉他)是一把(原聲吉他)。
(原聲吉他)是一把(吉他)。
(吉他)是一種(樂器)。
這意味著如果有人想搜索吉他,或者原聲吉他,所有的「馬丁吉他」能被納入搜尋範圍中。並且那表明Scott可以說他有「馬丁」或「馬丁吉他」,然後計算機為他計算出其餘的部分。
實際上,我剛剛對你說了謊——它確切來說不是按照那種方式運行的,並且使用指針時會產生許多歧義,並且甚至動詞短語也可能是指針,但是總比湧現出很多術語要好(諸如:namespaces, URIs, prefixes, serialization, PURLs……)。我們將略過那個部分,僅僅關注必要的事實:在語義網中的一切描述都是有URL的(或者URI之類)。真正的意思是說RDF是關於網絡數據的數據(或者叫元數據)。有時RDF會描述其他的RDF。因此你看到了怎樣使用全部語法的陳述,並且希望建造能自己思考的語義網嗎?綜合像那樣的陳述?是嗎?現在真的跟上(我的思路)了?是的,沒有人做這個。
因此Google 使用爬過RDF並建立索引的方法把每個人都聯繫在一起。當然,連結匿名的買主與賣主是不夠的。還需要是有信譽評估。輸入「網絡信譽評估和等級框架」,會顯示各種各樣的信譽評估框架,但是最後這個會被W3C認證(在麻省理工學院和ECMA的核事故之前),它現在是標準。他怎樣運行呢?像這樣:
在Kara Dobbs的站點上,我們找到這樣的敘述:
[Kara Dobbs]說(Scott Rahin)是(可信任的)。
在James Drevin的站點上,我們找到這樣的陳述:
[James Drevin]說(Scott Rahin)是(可信任的)。
等等。很好——但是你怎樣知道如何首先相信別人?
跟著我的思路:
在花旗銀行的站點上:
[花旗銀行]說(Scott Rahin)是(可信任的)。
在萬事達卡的站點上:
[萬事達卡]說(Scott Rahin)是(可信任的)。
然後在Google裡面:
[Google信譽評估服務]說(Scott Rahin)是(可信任的)。
並且如果
[花旗銀行 ]說(Kara Dobbs等人)都是(可信任的)。
然後你開始看出來它們全都是一致的,哪怕別人有一丁點的不誠實,你都會知道,實際上這種感覺很好。現在,如果關於信譽評估、真實的狀況、人類行為種種問題上升到10億個,我們不必需要查看30萬億個頁面,只相信它現在起作用就可以了。並且這一類的許多其他材料就像這樣子:
[美國社會保險管理機構]說(Pete Jefferson)在(1992)年出生。
這表明Pete Jefferson能從因特網中下載成人的錄像和視頻遊戲,因為他19歲了並且有一個社會安全號碼。無論如何,不能給未成年人授予安全號碼。並且不能忽視市民們通過自由分支的表述:
[Sherriff,來自德克薩斯的達拉斯]說(Martin Chalbarinstik)是一個(性侵犯慣犯)。
[Sherriff,來自德克薩斯的達拉斯]說(Dave Trebuchet)有一個(退回支票)。
[美國,綠黨]說(Susan Petershaw)是一名(成員)。
數據庫具有很強大的能力,它們集合的數據非常之多,它們還能關涉隱私,但是不允許作者利用冷酷的機器通過毫無根據的描述,來破壞我們的公民自由權,讓我們繼續前行。
無論如何,當你考慮它的時候,你看出Google為什麼總能很自然地把它們集合到一起。Google已經搜索了整個網絡。Google已經有數千台獨立的機器構成一種分佈框架。Google已經在頁面中找到了鏈接,這是建造它的索引的方式。 Google的搜索引擎用數百萬個變量解決方程式。在RDF裡語義的網絡內容,正是另一個搜索問題,另一套方程式而已。主要的問題在於首先得到信息;想出用它做什麼;從所有的工作中贏利;並且保持它被更新……
Google 市場經理
嗯,首先你需要信息。不過要人們僅僅在一台服務器上找到它,就好比一場混亂——因此讓我們看看「Google市場經理」,一個為Windows、Unix和Macintosh設計的小軟件。市場經理,或者簡稱MM,看起來像一張有規律的電子錶格,允許你列舉關於自己的信息,你想要出售的東西,你想要買的東西……它基本上是一名「邏輯語句的編輯」,只不過偽裝成一張電子錶格而已。人們輸入他們的名字,地址和其它關於他們自己的信息,然後,他們輸入正出售的東西,MM就會保存成RDF 格式文件,傳遞給他們選擇的服務器 ——並且把一個「連接測試程序(ping)」告訴Google,從而不斷改進他們的索引。
當它被開發出來的時候,MM真具有魔法般的魅力。假如你想出售一本書。在分類中你輸入「書」,MM就會查詢開放產品分類法,然後返回詢問你,它是否是一本精裝書、平裝書、用過的、新的、收集的等等。開放產品分類法本質上是一個結構化辭典,並且它將迅速成為描述出售產品的絕對標準。
然後你把書背面ISBN 號碼輸入進去,確認一下,MM就會自動返回填寫作者、版權、頁數和簡介——它只用RDF查詢了一下服務器,獲得它,計算它,返回給你。 如果你是一個小的出版社,你可以列舉你的目錄。如果你有《憤怒的葡萄》的第一版,你可以描述它並且給一個最低的可接受價格,它將在Google拍賣分類中出現。當Google 解釋被輸入的描述、大概符合電子錶格中的東西時,MM的多數小巧的功能實際在那些服務器上。如果你輸入汽車,它會詢問你顏色。 如果你輸入酒,它會詢問葡萄收穫期、葡萄園位置、多少瓶酒。然後,當某人尋找1998的Merlot酒時,你的葡萄酒信息就會列在目錄頂端。
你也能通過MM為高額時段或者大宗項目購買廣告,並且能跟蹤這些廣告的投放情況;它在漂亮的桌面上被全部升級和更新。你也能在網絡上隨時察看同步數據,但是使用MM是美好、快速、最優的。 當你買東西時,它在你的「購買」欄裡列舉項目,通過購買商品的類型來排列,這樣很容易打印出賬目,並為你和那好地記錄下來。
因此,就像我們說過的,Google允許你尋找買方與賣方,然後,使用一種「厚臉皮」的服務從無所不在的貝寶複製過來,交易的費用是1.75%。當然,人們能通過寄支票或者當面交付的方式避免1.75%的費用,但是對大多數交易來說,使用迅速而便宜的服務很不錯——1.75%費用加上投遞廣告和能到達全球的範圍,並且你能通過賬戶平穩地流動數百萬美元。
Amazon和Ebay,還記得它們嗎?無疑地看到了這項新產品並且意識到了他們所處的困境。為了去和Google競爭,他們必須「開創自己的商業模式」——把他們的數據庫交給不可理喻的網絡。因此,在「最優秀公司風格」的掩飾下,他們兩面下注並且什麼也沒做。
儘管他們很低調,但不久之後各種各樣的服務競相出現,就像Google一樣搜索了相同的數據,提供更便宜的交易價格。但是Google有品牌、信任和利潤。
超過100萬的個人在2年內接受並且開始使用新的服務——基於語義網購物。在這2年時間,Google大約有3億美元的資金流動——其中交易的淨額達450萬美元。但是,就像Ebay和Amazon曾經強迫消費者把生意帶到網絡上面來,口頭傳播開始發揮它的魔力。自從尋找想購買的東西變得容易了,並且MM也很容易下載和運行,到2006年訪問Google市場交易的人數增長到1000萬。
Google個人代理
現在,搜索已經不能滿足人們的需求了,還需要服務。你需要計算機幫助你。因此Google也開發出個人代理——本質上,它是一個經常查詢Google的小軟件,當它發現你正在語義網上尋找什麼時,就會寄給你電子郵件。
想知道哪個服務的電話資費更便宜?問問google代理吧。想知道Wholand主題公園什麼時候會在倫敦以外開放?問問google代理吧。或者你的妻子什麼時候更新她網絡上的日程,或者MSFT的價格什麼時候會上升到3 美元,或者加納的政治局勢什麼時候會觸到火線。你甚至能編程序讓它為你談判——如果它發現一本首版完好的《Paterson》在2000美元以下,它會先出價低於詢問價500美元,然後從那兒往上一點點提價。在你和賣方之間是匿名的,如果你有正確的帳號它甚至是免費的,沒有人從中勒索。反而,不使用它買東西會被認為落伍了。就像普通Google搜索與語義網命題邏輯的協商,個人代理也做同樣的事情——根據預先確定的規則,它每隔幾分鐘就以獨特的方式這樣做。
Google認證服務
最後,Google意識到他們能通過提供認證和分等級服務,來實現「真實的網絡」的想法,回答一張調查表需要每年15美元,其中有你的信用調查,還要填入一些銀行賬戶信息。但是人們會註冊它,因為Google就是市場;贊成Google的更甚於對政府的信任。
你的點對點「陪審團」
因為全部信息都以RDF形式存在,Google自己的策略會考慮利用它。Google市場經理的免費克隆版本開始出現,其他搜索引擎開始連1.75%的手續費都削減了,努力找到其他的收入模式。點對點模式一直是MP3和OGG格式的最愛,回到包括實時銷售數據集合中,傳遍成千上萬台志願者的機器——Google也使用相同的模式,卻是個人分佈式的模式。Amazon和Ebay開始在站點上自動包括已收集的RDF數據,削減了一切花費,使它與現有拍賣和待賣物品相結合。
在2006年,花旗銀行Drop Box賬戶開戶費從100美元/月,然後30 美元,然後15 美元,一路下降到5美元/月。Drop Box賬戶由唯一號碼認證,並且只能得到存款(後來能轉移到其他賬戶和存錢了)。它們甚至有URL地址,並且使用金融轉移協議。輕輕一點你的瀏覽器到account://382882-2838292-29-1939,然後輸入你想要存的錢數。只要不遺失drop box號碼就不會有風險,而且不用花手續費。銀行在聯邦監督契約帳戶裡保存了存錢的信息。任何人能公開他們的銀行帳號,根本不用中間人就能出售他們的東西了。
就像音樂公司以前一樣感受到了壓力,他們的目光轉向了點對點市場,Google把費用下降到1%,允許MM用戶使用Drop Box賬戶,並且對MM軟件和服務的購買者每年收取25美元,而對使用者仍然免費。在緊張的幾個月過去之後,Google發現多數用戶出售的東西超過十個,他們很高興買這品牌的產品;但點對點網絡被認為不那麼值得信任,人們認為它是與Google廣告相聯繫的。Google也意識到他們也能提供Drop Box賬戶,並且把它們捆綁在股票和金融市場商業賬戶上,它使得我們跨過了複雜而未獲解決的問題。如果你對此感興趣,就去讀讀Tom Rawley的《The Dragon in the Chicken Coop》吧。
Google的金融服務當然能自動被插入你的MM股票交易中;現在它們正已25000倍的收入做生意,預示著「新新新新經濟」消息的來臨。你在這兒得不到這樣的預示;當他們一旦把它做成了,競爭將是殘酷的。Google在過去不到十年的時間裡是夢幻公司,但是他們最終會減慢速度,這正是完成他們的哲學博士論文的時候。並且我確信他們會這樣的。
一個恐怖的語義化未來?
未來語義網的文化將很難處理。隱私是被密切關心的,但是保留太多的隱私卻無益。記得那些分類法嗎?嗯,一群人在開曼群島之外研製一種「魔鬼分類法」——一種特殊牌子遊艇的內部零件的辭典目錄,但是除了在紙上,實際上建立遊艇的公司從未存在過。他們其實是武器和藥品走私組織。當某人說」裝配」時,意思是大火力的自動步槍。厚帆布是可卡因。一台發動機是武器級別的钚的別稱。
因此,你在與一位妄自尊大的非洲共和國領導人在革命期間會面時,你僱用了一名移居國外的俄羅斯科學家,你的銀行賬戶內有販賣海洛因得來的60億利潤,並且你需要買一些武器級別的钚。誰來為你做這事兒?Google 個人代理,表面上你只不過為遊艇買了一台新發動機而已(雖然1800萬美元稍微有點貴)。如果你正通過「魔鬼分類法」出售鋁制咖啡壺——或者應該叫做蠻純的海洛因。你可能說,因此你彌補了這種差別。
突然作為犯罪策劃者的最大的問題產生了——發現從沒出賣你的那個賣方跑路了。由於那麼多賣方,你甚至能討價還價。出售钚就像出售馬丁吉他那樣順利、簡單、匿名。這難道不能發生嗎?一些人說它能,並解釋說Mandatory Metadata Review法案正在國會的審議議程中,全部RDF必須被引向公眾分類法。就像那個人所說的,你可以生活在有趣的年代。這是誰說的?在Google上查查吧。
分享至PLURK 噗浪
分享至FACEBOOK 臉書
July 26, 2002 By Paul Ford
一個虛構的故事,關於語義網的劇本。2009 年商業雜誌上的短篇特寫。請注意這篇文章是2002年寫的。
這真讓人難以置信,Google(現在世界上最大的獨立在線交易市場) 在僅僅8年多一點的時間就登上了舞台, 過去那可是Amazon和Ebay的統治領域。怎麼Google 就成為了世界上最大的獨立在線交易市場呢?
很好,簡而言之,答案就是「語義網」(一會兒我再告訴你這是什麼)。當Amazon和Ebay各自繼續以每季贏利10億和18億美元的時候,任何人都認為這是成功的,但Google在網絡交易市場每年盈利170億美元則被認定是更加成功的故事,前所未有的——「新經濟」。
Amazon和Ebay都努力開發虛擬交易市場:他們盡可能地外包庫存。然後,通過各種各樣的方法,把買主和賣主吸引到同一件商品上,從交易中抽取利潤。
對於Amazon來說,那意味著售賣新(商品)項目,或者允許眾多用戶賣出他們使用過的商品。對Ebay而言,它意味著把招標人和買主吸引在一起。一旦你被吸引進來, 這種途徑是極其有利潤的,它還是快速的,通過電話、電子郵件和數據庫管理。這很有效。
再來看看Google。在2002 年以前, 它是一個搜索引擎,依靠其廣告盈利。與此同時, 自1998年以來,「語義網」的理念獲得了少數人的關注,並吸引了與日俱增的這個圈子的人們。
什麼是語義網呢? 在其心臟部分, 這僅僅是一個以計算機能理解的方法來描述事物的;當然,它並不理解這是怎麼一回事,而是邏輯,就像在高中學的:
如果A是B的朋友, 那麼B就是A的朋友。
吉姆有一個朋友叫保羅。
所以,保羅有一個朋友叫吉姆。
使用的標記語言叫做RDF (在這兒是首字母的縮略, 因此你不妨學會它——它代表資源描述框架規範Resource Description Framework), 你可以把這樣的邏輯語句放到互聯網上,「網絡爬蟲」就能收集它們,並且語句能被搜索、分析、處理。它與正常搜索不同之處是, 語句可能被結合起來。所以,如果我在吉姆的站點上看到一句話「吉姆是保羅的朋友」,這時有人搜索了「保羅的朋友們」,即使保羅的網站沒有提到吉姆, 我們也會得知吉姆認為自己是保羅的朋友。
我們肯定也想知道其它的事情?比如A和B都是汽車賣主,但A賣的Miatas車比B要便宜百分之十。比如Jan Hammer 70 年代在Mahavishnu Orchestra專輯中使用的keyboards樂器。比如狗有爪子。比如你要求一台特殊型號的電腦,擁有新的主板和更快的總線,可以被升級到奔騰18。語義萬維網不是關於頁面和鏈接的, 它是考慮事物之間聯繫的——是否一件事是另一件事的一部分, 或者東西多少錢, 或什麼時候發生。
語義網最初只是作為Web缺乏「聰明」的補充——並且許多早期工作就像是安排日程和計劃, 和表述人與人之間的關係。在2003年末以前, 當Google 開始在語義網開發上作了一系列實驗的時候 (二年以後進入了他們的研究實驗室),這仍然幾乎是沒有人瞭解,並且很少人經常使用的東西, 除了在邏輯、計算機科學、人工智能方面有基礎知識的研究員。科研曲線象峭壁一樣陡, 並且對於編程人員來說,並沒有足夠的刺激來值得攀登它,也沒有從新的優勢中來研究世界的吸引力。
未來被描述的語義網,會使你更加容易預定牙醫的時間, 更新你的計算機, 檢查培訓計劃, 和協調汽車零件的發貨(時間)。它會使尋找東西更加容易。或許包括所有巨大的東西,巨大到以百萬美元起價。但不敢肯定對習慣於寫支票的人是否有足夠的誘惑, 特別是在他們經歷了95次的.com破產之後。他們看見的所有都是Web——(使他們損失了)幾個口袋和幾百萬的金錢——只不過有個「語義」在它前面修飾罷了。
Semantics vs. Syntax, Fight at 9
一件事物的語義與它的意義相關。它是一個很是模糊的東西,但是在人工智能的世界裡,這個目標將會是從句法中得出語義。至關重要的問題在於,如果你有一大堆東西整齊的按照句法規則排列成能為計算機所識別的結構,你又怎麼能從中得到意義呢?句法學如何成為語義學?人腦對此非常在行,但是對於計算機來說則是困難異常。他們對於句法感到頭疼。只要你用結構化的表達方式,就可以告訴他們任何事情,但是他們卻無法得到意義。他們會將「身有餘而心不足」這句話翻譯成「肉裡面充滿了星星但是伏特加酒是用粉紅色的羽毛做成」,像俄語一樣。
所以人們猜想,只有從句法合理的語句中才能得到真正令人感興趣的東西。實際上,你需要的是一個價值連城的腦袋。現在沒有人能證明這種方式的有效,而它的倡導者則是CYC公司的一個名叫Doug Lenat的人,他早就上了Ashcroft主席的黑名單,被視為一個危險的知識分子,已經好久沒有他的影子了。但是這些關於語義網的基本卻令人深思的概念,直到現在仍然有著影響,即通過從多個人那裡同時獲得句法,進而在他們的集合中獲得意義。
正如你所知道的,電腦仍然在聽我們的話。但是當語義網技術成熟發展起來以後,這些中心化的數據庫——例如Amazon和Ebay,他們都是有著眾多子條目的中心化數據庫–將會散落到網絡的每一處。每個人都將會有自己的那一份數據庫,他們自己的迷宮。發佈這些數據很容易,但是問題在於如何將他們聚合在一起。即使對於一些程序員來說,創建一份RDF文件也是很困難的。
這些都將會逐漸的改變,到了2004年的,Google將會有三種服務:Google市場搜索,Google個人代理和Google認證經理,以及一個軟件:Google市場經理。
Google的市場交易搜索
市場搜索位於Google語義搜索特徵的最重要的部分,而且差不多每一個瀏覽它的人至少會使用一次。你僅僅需要簡單地鍵入:
出售:「馬丁」牌吉他
來看看想買馬丁牌吉他的人的名單
購買:「馬丁」牌吉他
這是用來察看賣方的名單。
Google要求並且記得:你的郵編、按照價格組織的吉他名單中使用簡單的排序控制、狀態、型號、新的還是用過的,以及接近(的價格)。頁面是由Google的「傳統」非語義Web搜尋工具產生的,考慮在Web上長期最佳的匹配,並鏈接到馬丁型號和買者嚮導的信息,以及Google用戶新聞組的文章。還會鏈接到Epinions這樣的站點以彌補紕漏。
因此Google 市場搜索在哪裡得到信息呢?Google是以相同的方式找到它所需要的信息的——通過爬遍它找到的所有網絡和索引。而現在,它正尋找RDDL文件,它會指向RDF 文件,包含這樣的邏輯語句:
(Scott Rahin)住址的郵政編碼 (11231)
(Scott Rahin)電子郵箱地址(ford@ftrain.com)
(Scott Rahin)擁有(馬丁吉他)
[Scott的](馬丁吉他)型號是(245)。
[Scott的](馬丁吉他)可以在(http://ftrain.com/picture/martin.jpg)這裡看見
[Scott的](馬丁吉他)價值(900美元)
[Scott的](馬丁吉他)狀況(良好)
[Scott的](馬丁吉他)可以被描述成「保存得很好,並且很少玩(傷心啊!)。美妙,圓潤的聲音和一套多餘的吉他弦。我很高興能向順便拜訪的人展示它,或者在紐約市內的任何地方交付它」。
理解上面語句最重要的部分不只是在方括號和圓括號之間,而是指針。(Scott Rahin)是指向http://ftrain.com/people/Scott的一個指針。(馬丁牌原聲吉他)是指向URL的指針,它會反向參考包含其他邏輯語句的專業知識數據庫,像這樣:
(馬丁吉他)是一把(原聲吉他)。
(原聲吉他)是一把(吉他)。
(吉他)是一種(樂器)。
這意味著如果有人想搜索吉他,或者原聲吉他,所有的「馬丁吉他」能被納入搜尋範圍中。並且那表明Scott可以說他有「馬丁」或「馬丁吉他」,然後計算機為他計算出其餘的部分。
實際上,我剛剛對你說了謊——它確切來說不是按照那種方式運行的,並且使用指針時會產生許多歧義,並且甚至動詞短語也可能是指針,但是總比湧現出很多術語要好(諸如:namespaces, URIs, prefixes, serialization, PURLs……)。我們將略過那個部分,僅僅關注必要的事實:在語義網中的一切描述都是有URL的(或者URI之類)。真正的意思是說RDF是關於網絡數據的數據(或者叫元數據)。有時RDF會描述其他的RDF。因此你看到了怎樣使用全部語法的陳述,並且希望建造能自己思考的語義網嗎?綜合像那樣的陳述?是嗎?現在真的跟上(我的思路)了?是的,沒有人做這個。
因此Google 使用爬過RDF並建立索引的方法把每個人都聯繫在一起。當然,連結匿名的買主與賣主是不夠的。還需要是有信譽評估。輸入「網絡信譽評估和等級框架」,會顯示各種各樣的信譽評估框架,但是最後這個會被W3C認證(在麻省理工學院和ECMA的核事故之前),它現在是標準。他怎樣運行呢?像這樣:
在Kara Dobbs的站點上,我們找到這樣的敘述:
[Kara Dobbs]說(Scott Rahin)是(可信任的)。
在James Drevin的站點上,我們找到這樣的陳述:
[James Drevin]說(Scott Rahin)是(可信任的)。
等等。很好——但是你怎樣知道如何首先相信別人?
跟著我的思路:
在花旗銀行的站點上:
[花旗銀行]說(Scott Rahin)是(可信任的)。
在萬事達卡的站點上:
[萬事達卡]說(Scott Rahin)是(可信任的)。
然後在Google裡面:
[Google信譽評估服務]說(Scott Rahin)是(可信任的)。
並且如果
[花旗銀行 ]說(Kara Dobbs等人)都是(可信任的)。
然後你開始看出來它們全都是一致的,哪怕別人有一丁點的不誠實,你都會知道,實際上這種感覺很好。現在,如果關於信譽評估、真實的狀況、人類行為種種問題上升到10億個,我們不必需要查看30萬億個頁面,只相信它現在起作用就可以了。並且這一類的許多其他材料就像這樣子:
[美國社會保險管理機構]說(Pete Jefferson)在(1992)年出生。
這表明Pete Jefferson能從因特網中下載成人的錄像和視頻遊戲,因為他19歲了並且有一個社會安全號碼。無論如何,不能給未成年人授予安全號碼。並且不能忽視市民們通過自由分支的表述:
[Sherriff,來自德克薩斯的達拉斯]說(Martin Chalbarinstik)是一個(性侵犯慣犯)。
[Sherriff,來自德克薩斯的達拉斯]說(Dave Trebuchet)有一個(退回支票)。
[美國,綠黨]說(Susan Petershaw)是一名(成員)。
數據庫具有很強大的能力,它們集合的數據非常之多,它們還能關涉隱私,但是不允許作者利用冷酷的機器通過毫無根據的描述,來破壞我們的公民自由權,讓我們繼續前行。
無論如何,當你考慮它的時候,你看出Google為什麼總能很自然地把它們集合到一起。Google已經搜索了整個網絡。Google已經有數千台獨立的機器構成一種分佈框架。Google已經在頁面中找到了鏈接,這是建造它的索引的方式。 Google的搜索引擎用數百萬個變量解決方程式。在RDF裡語義的網絡內容,正是另一個搜索問題,另一套方程式而已。主要的問題在於首先得到信息;想出用它做什麼;從所有的工作中贏利;並且保持它被更新……
Google 市場經理
嗯,首先你需要信息。不過要人們僅僅在一台服務器上找到它,就好比一場混亂——因此讓我們看看「Google市場經理」,一個為Windows、Unix和Macintosh設計的小軟件。市場經理,或者簡稱MM,看起來像一張有規律的電子錶格,允許你列舉關於自己的信息,你想要出售的東西,你想要買的東西……它基本上是一名「邏輯語句的編輯」,只不過偽裝成一張電子錶格而已。人們輸入他們的名字,地址和其它關於他們自己的信息,然後,他們輸入正出售的東西,MM就會保存成RDF 格式文件,傳遞給他們選擇的服務器 ——並且把一個「連接測試程序(ping)」告訴Google,從而不斷改進他們的索引。
當它被開發出來的時候,MM真具有魔法般的魅力。假如你想出售一本書。在分類中你輸入「書」,MM就會查詢開放產品分類法,然後返回詢問你,它是否是一本精裝書、平裝書、用過的、新的、收集的等等。開放產品分類法本質上是一個結構化辭典,並且它將迅速成為描述出售產品的絕對標準。
然後你把書背面ISBN 號碼輸入進去,確認一下,MM就會自動返回填寫作者、版權、頁數和簡介——它只用RDF查詢了一下服務器,獲得它,計算它,返回給你。 如果你是一個小的出版社,你可以列舉你的目錄。如果你有《憤怒的葡萄》的第一版,你可以描述它並且給一個最低的可接受價格,它將在Google拍賣分類中出現。當Google 解釋被輸入的描述、大概符合電子錶格中的東西時,MM的多數小巧的功能實際在那些服務器上。如果你輸入汽車,它會詢問你顏色。 如果你輸入酒,它會詢問葡萄收穫期、葡萄園位置、多少瓶酒。然後,當某人尋找1998的Merlot酒時,你的葡萄酒信息就會列在目錄頂端。
你也能通過MM為高額時段或者大宗項目購買廣告,並且能跟蹤這些廣告的投放情況;它在漂亮的桌面上被全部升級和更新。你也能在網絡上隨時察看同步數據,但是使用MM是美好、快速、最優的。 當你買東西時,它在你的「購買」欄裡列舉項目,通過購買商品的類型來排列,這樣很容易打印出賬目,並為你和那好地記錄下來。
因此,就像我們說過的,Google允許你尋找買方與賣方,然後,使用一種「厚臉皮」的服務從無所不在的貝寶複製過來,交易的費用是1.75%。當然,人們能通過寄支票或者當面交付的方式避免1.75%的費用,但是對大多數交易來說,使用迅速而便宜的服務很不錯——1.75%費用加上投遞廣告和能到達全球的範圍,並且你能通過賬戶平穩地流動數百萬美元。
Amazon和Ebay,還記得它們嗎?無疑地看到了這項新產品並且意識到了他們所處的困境。為了去和Google競爭,他們必須「開創自己的商業模式」——把他們的數據庫交給不可理喻的網絡。因此,在「最優秀公司風格」的掩飾下,他們兩面下注並且什麼也沒做。
儘管他們很低調,但不久之後各種各樣的服務競相出現,就像Google一樣搜索了相同的數據,提供更便宜的交易價格。但是Google有品牌、信任和利潤。
超過100萬的個人在2年內接受並且開始使用新的服務——基於語義網購物。在這2年時間,Google大約有3億美元的資金流動——其中交易的淨額達450萬美元。但是,就像Ebay和Amazon曾經強迫消費者把生意帶到網絡上面來,口頭傳播開始發揮它的魔力。自從尋找想購買的東西變得容易了,並且MM也很容易下載和運行,到2006年訪問Google市場交易的人數增長到1000萬。
Google個人代理
現在,搜索已經不能滿足人們的需求了,還需要服務。你需要計算機幫助你。因此Google也開發出個人代理——本質上,它是一個經常查詢Google的小軟件,當它發現你正在語義網上尋找什麼時,就會寄給你電子郵件。
想知道哪個服務的電話資費更便宜?問問google代理吧。想知道Wholand主題公園什麼時候會在倫敦以外開放?問問google代理吧。或者你的妻子什麼時候更新她網絡上的日程,或者MSFT的價格什麼時候會上升到3 美元,或者加納的政治局勢什麼時候會觸到火線。你甚至能編程序讓它為你談判——如果它發現一本首版完好的《Paterson》在2000美元以下,它會先出價低於詢問價500美元,然後從那兒往上一點點提價。在你和賣方之間是匿名的,如果你有正確的帳號它甚至是免費的,沒有人從中勒索。反而,不使用它買東西會被認為落伍了。就像普通Google搜索與語義網命題邏輯的協商,個人代理也做同樣的事情——根據預先確定的規則,它每隔幾分鐘就以獨特的方式這樣做。
Google認證服務
最後,Google意識到他們能通過提供認證和分等級服務,來實現「真實的網絡」的想法,回答一張調查表需要每年15美元,其中有你的信用調查,還要填入一些銀行賬戶信息。但是人們會註冊它,因為Google就是市場;贊成Google的更甚於對政府的信任。
你的點對點「陪審團」
因為全部信息都以RDF形式存在,Google自己的策略會考慮利用它。Google市場經理的免費克隆版本開始出現,其他搜索引擎開始連1.75%的手續費都削減了,努力找到其他的收入模式。點對點模式一直是MP3和OGG格式的最愛,回到包括實時銷售數據集合中,傳遍成千上萬台志願者的機器——Google也使用相同的模式,卻是個人分佈式的模式。Amazon和Ebay開始在站點上自動包括已收集的RDF數據,削減了一切花費,使它與現有拍賣和待賣物品相結合。
在2006年,花旗銀行Drop Box賬戶開戶費從100美元/月,然後30 美元,然後15 美元,一路下降到5美元/月。Drop Box賬戶由唯一號碼認證,並且只能得到存款(後來能轉移到其他賬戶和存錢了)。它們甚至有URL地址,並且使用金融轉移協議。輕輕一點你的瀏覽器到account://382882-2838292-29-1939,然後輸入你想要存的錢數。只要不遺失drop box號碼就不會有風險,而且不用花手續費。銀行在聯邦監督契約帳戶裡保存了存錢的信息。任何人能公開他們的銀行帳號,根本不用中間人就能出售他們的東西了。
就像音樂公司以前一樣感受到了壓力,他們的目光轉向了點對點市場,Google把費用下降到1%,允許MM用戶使用Drop Box賬戶,並且對MM軟件和服務的購買者每年收取25美元,而對使用者仍然免費。在緊張的幾個月過去之後,Google發現多數用戶出售的東西超過十個,他們很高興買這品牌的產品;但點對點網絡被認為不那麼值得信任,人們認為它是與Google廣告相聯繫的。Google也意識到他們也能提供Drop Box賬戶,並且把它們捆綁在股票和金融市場商業賬戶上,它使得我們跨過了複雜而未獲解決的問題。如果你對此感興趣,就去讀讀Tom Rawley的《The Dragon in the Chicken Coop》吧。
Google的金融服務當然能自動被插入你的MM股票交易中;現在它們正已25000倍的收入做生意,預示著「新新新新經濟」消息的來臨。你在這兒得不到這樣的預示;當他們一旦把它做成了,競爭將是殘酷的。Google在過去不到十年的時間裡是夢幻公司,但是他們最終會減慢速度,這正是完成他們的哲學博士論文的時候。並且我確信他們會這樣的。
一個恐怖的語義化未來?
未來語義網的文化將很難處理。隱私是被密切關心的,但是保留太多的隱私卻無益。記得那些分類法嗎?嗯,一群人在開曼群島之外研製一種「魔鬼分類法」——一種特殊牌子遊艇的內部零件的辭典目錄,但是除了在紙上,實際上建立遊艇的公司從未存在過。他們其實是武器和藥品走私組織。當某人說」裝配」時,意思是大火力的自動步槍。厚帆布是可卡因。一台發動機是武器級別的钚的別稱。
因此,你在與一位妄自尊大的非洲共和國領導人在革命期間會面時,你僱用了一名移居國外的俄羅斯科學家,你的銀行賬戶內有販賣海洛因得來的60億利潤,並且你需要買一些武器級別的钚。誰來為你做這事兒?Google 個人代理,表面上你只不過為遊艇買了一台新發動機而已(雖然1800萬美元稍微有點貴)。如果你正通過「魔鬼分類法」出售鋁制咖啡壺——或者應該叫做蠻純的海洛因。你可能說,因此你彌補了這種差別。
突然作為犯罪策劃者的最大的問題產生了——發現從沒出賣你的那個賣方跑路了。由於那麼多賣方,你甚至能討價還價。出售钚就像出售馬丁吉他那樣順利、簡單、匿名。這難道不能發生嗎?一些人說它能,並解釋說Mandatory Metadata Review法案正在國會的審議議程中,全部RDF必須被引向公眾分類法。就像那個人所說的,你可以生活在有趣的年代。這是誰說的?在Google上查查吧。
BLOG外掛-2008年365天寵物顯示日曆
這是由http://www.365calendar.net/提供的部落格外掛,包含了裡頭有網友們投稿的各種類型寵物,包含狗狗,貓,兔鼠,鳥兒們的寵物照片,他們收集了365張會員們投稿的寵物照片,讓你每天在外掛裡都可以看到不同的寵物照片,此外投稿數目較多的狗狗類,甚至還有分犬種,你可以選擇自己喜歡的犬種或是綜合類的日曆來掛,是喜歡寵物的你不能錯過的部落格外掛喔!
2008年日曆外掛分為:狗狗(全部綜合或單一犬種)、貓、小型寵物(兔鼠類)、鳥兒,每天照片都會不同
網址及語法:http://www.365calendar.net/special/blogparts.html
範例截圖(不知道為什麼小倩的天空部落貼這個出不來):

實際範例:
狗狗全部系列4:
兔兔系列:
分享至PLURK 噗浪
分享至FACEBOOK 臉書
2008年日曆外掛分為:狗狗(全部綜合或單一犬種)、貓、小型寵物(兔鼠類)、鳥兒,每天照片都會不同
網址及語法:http://www.365calendar.net/special/blogparts.html
範例截圖(不知道為什麼小倩的天空部落貼這個出不來):

狗狗全部系列4:
兔兔系列:
2008年2月18日 星期一
什麼是『Pervasive Computing』 (無所不在的運算)?
擷取自: http://www.iiiedu.org.tw/knowledge/knowledge20031231_1.htm
講師: 資策會數位教育研究所講師 劉翰卿
記得,在多年以前有一部電視影集的對話是如此說的:「夥計,快到門口來接我呀!」、「老哥,撐著點,我馬上就到!」沒錯,這就是《 霹靂遊俠 》中的黃金拍檔──是一輛會說話、近乎全能的電腦車。而〝李麥克〞,憑著車上各項尖端設備,勇破各種奇案,打擊犯罪!!
您可以利用空檔、在夜闌人靜時分泡著一杯香醇的藍山咖啡,仔細地端詳卡內基美隆大學(Carnegie Mellon University)所發表的兩篇IEEE的期刊文章:『Project Aura:Toward Distraction-Free Pervasive Computing』 、『Aura: an Architectural Framework for User Mobility in Ubiquitous Computing Environments』。賞閱完後,您就會對『Pervasive Computing』一詞有個瞭解,但僅止於概略性的瞭解。關於『Pervasive Computing』一詞有人翻譯成『無所不在的運算』、或是『無處不在的運算』、甚至『普及運算』,然而不管怎麼樣地翻譯,實在難以一語道盡、完美詮釋這一個領域究竟是啥玩意兒,不過倒可從字面之意猜出它應該是跟我們未來的生活是息息相關的,而且是科技享樂主義者所樂觀其成的。
不知您是否和我的經驗一樣,在腦海中對Pervasive Computing所浮現的第一印象竟是霹靂遊俠的精彩畫面,以及許久以前所學過的CORBA規格,透過IDL作為互通的機制。不過,在仔細閱讀完這兩篇文獻的內容後,尤其在看完闡述Aura 的架構的篇幅後,突然又驚覺到好像跟我想像中的景象又有那麼地一點點不一樣。於是上網查詢了一些關於 Pervasive Computing 的一些主題資訊,才瞭解到Pervasive Computing/Ubiquitous Computing Environments(無所不在的運算環境)其實是很廣泛的,卡內基美隆大學所作的專案研究〝Aura〞只能算是其中的一小環而已。在中國大陸有學者提出〝筆式使用者界面開發工具〞研究、在歐美等先進國家又有人對〝可穿戴式的運算〞等進行相關的研究;不斷摸索中,直到看完了在家中Download了近兩個小時卡內基美隆大學所拍攝關於的Project Aura 的影片後,才意會到 “Aura” 它所代表的真正意涵。
的確,根據Moore's Law(摩爾定律)(*註一),未來電腦系統中最貴重的資產可能不會再是 CPU、記憶體、磁碟容量、或網路頻寬等等資源,取而代之的是人類的〝注意力(attention)〞。讓注意力集中,免於因繁複的電腦系統操作、效率等等問題而使得人類寶貴的注意力分散,造成不必要的危險或風險之發生;同時,有了注意力,才有機會發揮更大的創造力與想像力,激發出無窮的潛力,締造出更燦爛、絢麗與便利的美
好明天。而在這兩篇文章中提及一些重要課題,就是剛剛所述跟我想像中不太一樣的地方,這也促使我上網花了一些時間來予以釐清的觀念。
Current approaches to user mobility are based on one of four techniques, none of which fully achieves these goals.
1.
Support as much of a user’s computing needs as possible on a mobile machine.
2.
Compute via remote access to a computing server that stores a users personal state and preferences, much as X-terminals
do.
3.
Provide standard applications that are ported to and installed
in all environments. Those applications are extended to become
aware of user intention and mobility.
4.
Provide standard virtual platforms (such as the Java Virtual Machine) that enable mobile code to follow the user as
needed.
曾看過一份雜誌,它是如此描繪的:『五月天的下午,開著冷氣您乘坐在舒適豪華的Jaguar愛車裡,優雅舒適地徜徉於信義計劃區網狀的市區道路中,意氣風發的您不必為了惱人的單向、雙向行車問題而迷路或為了工作分派的問題而煩惱,因為您的車載電腦更勝於您美麗的女助理。“哈囉”,隨著熟悉的聲音,它提示您:30分鐘後您在台北101世界超高摩天大樓將有一個約會,並顯示從目前位置前往的路線圖,車程時間為20分鐘。您告訴它說“瞭解”,並結束對話。“哈囉”,它又提醒您,走另一條路,車程可能會多個10分鐘,但您可以順道買一杯您喜歡的StarBuck拿鐵咖啡。“謝謝您”,您爽朗的回答,您喜歡這個超人性化的提議。但您可能會因此而遲到,怎麼辦呢?不用擔心,它(您的夥計)早就為老哥您設想週到地送出一個簡訊給您的約會對象,您可以從容不迫地到達目的地就好!不必為了些微的耽擱而焦慮。畢竟,台北市長曾說過:行車安全最重要的啦!』
的確,這就是未來的IT應用,它不僅可以隨時隨地溝通資訊,還瞭解您的個人需求,它將是您最安全、最可信賴的伙伴。未來技術發展的兩大趨勢是無處不在的運算(Pervasive Computing/ Ubiquitous Computing Environments)和無線網絡服務。未來的基礎設施是看不見的,將來人們不用關心電腦,只需考慮與什麼人、做什麼事?要實現這個目標需要的正是時間。就正如今天我們家裡的水龍頭打開就有水,甚至還可能是您所需求溫度的水;透過一張票卡,悠遊台北甚至可以台灣各地走透透等等,而這一切就需要基礎管道的鋪設。對IT來說,這就是網絡服務。 而當今,全世界約有70%的資訊存放在資料庫中,我們必須有更強勁的方式去釋放這些資訊,有更簡單的方式去使用這些資訊,更有效率的方式去發揮這些資訊。有統計顯示,善用網絡服務可以使企業的成本降低40%。
與此同時,我們看到技術推動著所有人的生活,如藍牙連接PC,加上本地裝置,GPRS、3G等,無線連接、無處不在的運算可將不同的硬體連接在一起,裝置愈來愈人性化,體積越來越小,價格愈來愈低,功能越來越豐富。網絡服務將這些無處不在的裝置連接在一起,將資料帶入生活並進行整合,實現與外界的連繫。這就使得無處不在的運算環境不僅在企業工作中,甚至在日常生活中亦可使得資訊可以隨時隨地、隨心所欲的傳送。這種新的技術核心將成為我們生活環境的一部分,並將改變人類的文明生活。
若您有機會詳閱這兩篇文章的話,大概可以體會到無處不在的運算(Pervasive Computing/ Ubiquitous Computing Environments)算是當前電腦應用技術發展的新興領域,是多種電腦技術的融合,具有重要的理論研究價值和廣泛的應用前景,它將成為電腦應用領域中的一大新產業。
但要實現無處不在的技術環境,則必須要跨越許許多多的障礙與大大小小的鴻溝,包括網絡裝置的整合、可管理性、安全性、對異構平台支持以及可擴展性等等課題。而『Project Aura』才算剛起步而已,未來仍然還有一大段遙遠的路途要走。卡內基美隆大學所提的Aura架構看似簡單易懂(*註二),但實作起來卻是十足的充滿無限挑戰,所要結合的領域(Machine learning、Psychology、……)等等既多且深也廣,且讓我
們拭目以待。
註一:
摩爾定律(Moore's Law)是指:IC上可容納的電晶體數目,約每隔18個月便會增加一倍,性能也將提升一倍。
摩爾定律是由英特爾(Intel)名譽董事長摩爾經過長期觀察發現得之。摩爾定律是指一個尺寸相同的晶片上,所容納的電晶體數量,因製程技術的提升,每十八個月會加倍,但售價相同;晶片的容量是以電晶體(Transistor)的數量多寡來計算,電晶體愈多則晶片執行運算的速度愈快,當然,所需要的生產技術愈高明。若在相同面積的晶圓下生產同樣規格的IC,隨著製程技術的進步,每隔一年半,IC產出量就可增加一倍,換算為成本,即每隔一年半成本可降低五成,平均每年成本可降低三成多。就摩爾定律延伸,IC技術每隔一年半推進一個世代。摩爾定律是簡單評估半導體技術進展的經驗法則,其重要的意義在於長期而言IC製程技術是以一直線的方式向前推展,使得IC產品能持續降低成本,提升性能,增加功能。
台積電董事長張忠謀先生曾表示,摩爾定律在過去30年相當有效,未10
年間應該是依然適用。
註二:
內基美隆大學(Carnegie Mellon University)的專案研究—〝Aura〞概略架構

分享至PLURK 噗浪
分享至FACEBOOK 臉書
講師: 資策會數位教育研究所講師 劉翰卿
記得,在多年以前有一部電視影集的對話是如此說的:「夥計,快到門口來接我呀!」、「老哥,撐著點,我馬上就到!」沒錯,這就是《 霹靂遊俠 》中的黃金拍檔──是一輛會說話、近乎全能的電腦車。而〝李麥克〞,憑著車上各項尖端設備,勇破各種奇案,打擊犯罪!!
您可以利用空檔、在夜闌人靜時分泡著一杯香醇的藍山咖啡,仔細地端詳卡內基美隆大學(Carnegie Mellon University)所發表的兩篇IEEE的期刊文章:『Project Aura:Toward Distraction-Free Pervasive Computing』 、『Aura: an Architectural Framework for User Mobility in Ubiquitous Computing Environments』。賞閱完後,您就會對『Pervasive Computing』一詞有個瞭解,但僅止於概略性的瞭解。關於『Pervasive Computing』一詞有人翻譯成『無所不在的運算』、或是『無處不在的運算』、甚至『普及運算』,然而不管怎麼樣地翻譯,實在難以一語道盡、完美詮釋這一個領域究竟是啥玩意兒,不過倒可從字面之意猜出它應該是跟我們未來的生活是息息相關的,而且是科技享樂主義者所樂觀其成的。
不知您是否和我的經驗一樣,在腦海中對Pervasive Computing所浮現的第一印象竟是霹靂遊俠的精彩畫面,以及許久以前所學過的CORBA規格,透過IDL作為互通的機制。不過,在仔細閱讀完這兩篇文獻的內容後,尤其在看完闡述Aura 的架構的篇幅後,突然又驚覺到好像跟我想像中的景象又有那麼地一點點不一樣。於是上網查詢了一些關於 Pervasive Computing 的一些主題資訊,才瞭解到Pervasive Computing/Ubiquitous Computing Environments(無所不在的運算環境)其實是很廣泛的,卡內基美隆大學所作的專案研究〝Aura〞只能算是其中的一小環而已。在中國大陸有學者提出〝筆式使用者界面開發工具〞研究、在歐美等先進國家又有人對〝可穿戴式的運算〞等進行相關的研究;不斷摸索中,直到看完了在家中Download了近兩個小時卡內基美隆大學所拍攝關於的Project Aura 的影片後,才意會到 “Aura” 它所代表的真正意涵。
的確,根據Moore's Law(摩爾定律)(*註一),未來電腦系統中最貴重的資產可能不會再是 CPU、記憶體、磁碟容量、或網路頻寬等等資源,取而代之的是人類的〝注意力(attention)〞。讓注意力集中,免於因繁複的電腦系統操作、效率等等問題而使得人類寶貴的注意力分散,造成不必要的危險或風險之發生;同時,有了注意力,才有機會發揮更大的創造力與想像力,激發出無窮的潛力,締造出更燦爛、絢麗與便利的美
好明天。而在這兩篇文章中提及一些重要課題,就是剛剛所述跟我想像中不太一樣的地方,這也促使我上網花了一些時間來予以釐清的觀念。
Current approaches to user mobility are based on one of four techniques, none of which fully achieves these goals.
1.
Support as much of a user’s computing needs as possible on a mobile machine.
2.
Compute via remote access to a computing server that stores a users personal state and preferences, much as X-terminals
do.
3.
Provide standard applications that are ported to and installed
in all environments. Those applications are extended to become
aware of user intention and mobility.
4.
Provide standard virtual platforms (such as the Java Virtual Machine) that enable mobile code to follow the user as
needed.
曾看過一份雜誌,它是如此描繪的:『五月天的下午,開著冷氣您乘坐在舒適豪華的Jaguar愛車裡,優雅舒適地徜徉於信義計劃區網狀的市區道路中,意氣風發的您不必為了惱人的單向、雙向行車問題而迷路或為了工作分派的問題而煩惱,因為您的車載電腦更勝於您美麗的女助理。“哈囉”,隨著熟悉的聲音,它提示您:30分鐘後您在台北101世界超高摩天大樓將有一個約會,並顯示從目前位置前往的路線圖,車程時間為20分鐘。您告訴它說“瞭解”,並結束對話。“哈囉”,它又提醒您,走另一條路,車程可能會多個10分鐘,但您可以順道買一杯您喜歡的StarBuck拿鐵咖啡。“謝謝您”,您爽朗的回答,您喜歡這個超人性化的提議。但您可能會因此而遲到,怎麼辦呢?不用擔心,它(您的夥計)早就為老哥您設想週到地送出一個簡訊給您的約會對象,您可以從容不迫地到達目的地就好!不必為了些微的耽擱而焦慮。畢竟,台北市長曾說過:行車安全最重要的啦!』
的確,這就是未來的IT應用,它不僅可以隨時隨地溝通資訊,還瞭解您的個人需求,它將是您最安全、最可信賴的伙伴。未來技術發展的兩大趨勢是無處不在的運算(Pervasive Computing/ Ubiquitous Computing Environments)和無線網絡服務。未來的基礎設施是看不見的,將來人們不用關心電腦,只需考慮與什麼人、做什麼事?要實現這個目標需要的正是時間。就正如今天我們家裡的水龍頭打開就有水,甚至還可能是您所需求溫度的水;透過一張票卡,悠遊台北甚至可以台灣各地走透透等等,而這一切就需要基礎管道的鋪設。對IT來說,這就是網絡服務。 而當今,全世界約有70%的資訊存放在資料庫中,我們必須有更強勁的方式去釋放這些資訊,有更簡單的方式去使用這些資訊,更有效率的方式去發揮這些資訊。有統計顯示,善用網絡服務可以使企業的成本降低40%。
與此同時,我們看到技術推動著所有人的生活,如藍牙連接PC,加上本地裝置,GPRS、3G等,無線連接、無處不在的運算可將不同的硬體連接在一起,裝置愈來愈人性化,體積越來越小,價格愈來愈低,功能越來越豐富。網絡服務將這些無處不在的裝置連接在一起,將資料帶入生活並進行整合,實現與外界的連繫。這就使得無處不在的運算環境不僅在企業工作中,甚至在日常生活中亦可使得資訊可以隨時隨地、隨心所欲的傳送。這種新的技術核心將成為我們生活環境的一部分,並將改變人類的文明生活。
若您有機會詳閱這兩篇文章的話,大概可以體會到無處不在的運算(Pervasive Computing/ Ubiquitous Computing Environments)算是當前電腦應用技術發展的新興領域,是多種電腦技術的融合,具有重要的理論研究價值和廣泛的應用前景,它將成為電腦應用領域中的一大新產業。
但要實現無處不在的技術環境,則必須要跨越許許多多的障礙與大大小小的鴻溝,包括網絡裝置的整合、可管理性、安全性、對異構平台支持以及可擴展性等等課題。而『Project Aura』才算剛起步而已,未來仍然還有一大段遙遠的路途要走。卡內基美隆大學所提的Aura架構看似簡單易懂(*註二),但實作起來卻是十足的充滿無限挑戰,所要結合的領域(Machine learning、Psychology、……)等等既多且深也廣,且讓我
們拭目以待。
註一:
摩爾定律(Moore's Law)是指:IC上可容納的電晶體數目,約每隔18個月便會增加一倍,性能也將提升一倍。
摩爾定律是由英特爾(Intel)名譽董事長摩爾經過長期觀察發現得之。摩爾定律是指一個尺寸相同的晶片上,所容納的電晶體數量,因製程技術的提升,每十八個月會加倍,但售價相同;晶片的容量是以電晶體(Transistor)的數量多寡來計算,電晶體愈多則晶片執行運算的速度愈快,當然,所需要的生產技術愈高明。若在相同面積的晶圓下生產同樣規格的IC,隨著製程技術的進步,每隔一年半,IC產出量就可增加一倍,換算為成本,即每隔一年半成本可降低五成,平均每年成本可降低三成多。就摩爾定律延伸,IC技術每隔一年半推進一個世代。摩爾定律是簡單評估半導體技術進展的經驗法則,其重要的意義在於長期而言IC製程技術是以一直線的方式向前推展,使得IC產品能持續降低成本,提升性能,增加功能。
台積電董事長張忠謀先生曾表示,摩爾定律在過去30年相當有效,未10
年間應該是依然適用。
註二:
內基美隆大學(Carnegie Mellon University)的專案研究—〝Aura〞概略架構

雲端運算- Wikipedia
雲端運算
雲端運算(cloud computing,分散式運算技術的一種,其最基本的概念,是透過網路將龐大的運算處理程序自動分拆成無數個較小的子程序,再交由多部伺服器所組成的龐大系統經搜尋、運算分析之後將處理結果回傳給用戶。透過這項技術,網路服務提供者可以在數秒之內,達成處理數以千萬計甚至億計的資訊,達到和「超級電腦」同樣強大效能的網路服務。
最簡單的雲端運算技術在網路服務中已經隨處可見,例如搜尋引擎、網路信箱等,使用者只要輸入簡單指令即能得到大量資訊。
未來如手機、GPS等行動裝置都可以透過雲端運算技術,發展出更多的應用服務。
進一步的雲端運算不僅只做資料搜尋、分析的功能,未來如分析DNA結構、基因圖譜定序、解析癌症細胞等,都可以透過這項技術輕易達成。
推廣與發展
2007年10月,Google與IBM開始在美國大學校園,包括卡內基美隆大學、麻省理工學院、史丹佛大學、加州大學柏克萊分校及馬里蘭大學等,推廣雲端運算的計畫,這項計劃希望能降低分散式運算技術在學術研究方面的成本,並為這些大學提供相關的軟硬體設備及技術支援(包括數百台個人電腦及BladeCenter與System x伺服器,這些運算平臺將提供1600個處理器,支援包括Linux、Xen、Hadoop等開放原始碼平臺)。而學生則可以透過網路開發各項以大規模運算為基礎的研究計畫。
2008年1月30日,Google宣佈在台灣啟動「雲端運算學術計畫」,將與臺大、交大等學校合作,將這種先進的大規模、快速運算技術推廣到校園。
分享至PLURK 噗浪
分享至FACEBOOK 臉書
雲端運算(cloud computing,分散式運算技術的一種,其最基本的概念,是透過網路將龐大的運算處理程序自動分拆成無數個較小的子程序,再交由多部伺服器所組成的龐大系統經搜尋、運算分析之後將處理結果回傳給用戶。透過這項技術,網路服務提供者可以在數秒之內,達成處理數以千萬計甚至億計的資訊,達到和「超級電腦」同樣強大效能的網路服務。
最簡單的雲端運算技術在網路服務中已經隨處可見,例如搜尋引擎、網路信箱等,使用者只要輸入簡單指令即能得到大量資訊。
未來如手機、GPS等行動裝置都可以透過雲端運算技術,發展出更多的應用服務。
進一步的雲端運算不僅只做資料搜尋、分析的功能,未來如分析DNA結構、基因圖譜定序、解析癌症細胞等,都可以透過這項技術輕易達成。
推廣與發展
2007年10月,Google與IBM開始在美國大學校園,包括卡內基美隆大學、麻省理工學院、史丹佛大學、加州大學柏克萊分校及馬里蘭大學等,推廣雲端運算的計畫,這項計劃希望能降低分散式運算技術在學術研究方面的成本,並為這些大學提供相關的軟硬體設備及技術支援(包括數百台個人電腦及BladeCenter與System x伺服器,這些運算平臺將提供1600個處理器,支援包括Linux、Xen、Hadoop等開放原始碼平臺)。而學生則可以透過網路開發各項以大規模運算為基礎的研究計畫。
2008年1月30日,Google宣佈在台灣啟動「雲端運算學術計畫」,將與臺大、交大等學校合作,將這種先進的大規模、快速運算技術推廣到校園。
雲端運算cloud computing
本文擷取自 : http://mmdays.com/2008/02/14/cloud-computing/
前一陣子在新聞上看到不少有關於 Cloud Computing (雲端運算) 的報導,不過看看台灣的報導似乎都不是相當深入或是明確,於是我興起了寫這一篇文章的念頭。這篇文章是我自己對於雲端運算的理解,還希望各位讀者能一起參與討論,提供不同的見解。有機會的話,我也希望之後能夠繼續寫一些有關雲端運算中所包含的粗淺的技術介紹。
好吧,開門見山:雲端運算不是技術,它是概念。為什麼這樣說呢?因為 cloud computing 本身並不代表任何一項資訊科技的技術,它是一種電腦運算的概念,而一種概念就會有許多不同的方式去實踐,這個時候才會有不同的技術衍伸出來。就好像我們聽過 pervasive computing、ubiquitous computing、parallel computing 一樣,這些都是運算的概念,不是單指一項特定的技術。cloud computing 也不例外,它本質上就是代表分散式運算 (distributed computing) 的概念。而分散式運算說穿了,就是讓一些不同的電腦同時去幫你做事情、進行運算,所以你有兩台電腦也好、十萬台電腦也好,只要你有超過一台電腦,而且讓他們可以互相溝通,一起同時幫你做事情,恭喜你,這就是分散式運算。
好吧,如果雲端運算不過就是分散式運算罷了,故事就這樣結束也太沒意思了。那我們就繼續從其他名詞的出現繼續看下去好了。
大家可能同時也聽過 grid computing (網格運算) 這個名詞,相信滿多人覺得網格運算跟 cloud computing 很像。其實 cloud computing 在概念上跟 grid computing 並沒有非常嚴格的區隔或是很大的不同,兩者均可看成是 distributed computing (分散式運算) 衍伸出來的概念。grid computing 一詞出現得較早,將重點的概念放在異質系統之間運算資源的整合,簡單來說,就是讓不同等級的電腦、或是不同作業系統的電腦,彼此之間可以透過通訊標準來互相溝通,分享彼此的運算資源。在網際網路還沒有今天這麼發達之前,企業採用 grid computing,很大的原因是為了讓組織內部的 IT 資源達到更良好的使用率。
當大家努力去實現這樣的一個概念時,其實就促成了網際網路的蓬勃發展,因為網路本身就是在強調不同電腦之間的溝通以及合作,於是在各項基礎設施包括頻寬、通訊標準、電腦運算能力以及運算架構都逐漸發展成熟之後,提供給開發者或是一般使用者的網路服務便開始出現,這些網路服務 (Web Service) 提供給使用者簡單的介面來存取一些資源。當然一開始的時候,企業提供出來的,都是一些相當陽春的網路服務。
這些 Web Service 繼續發展下去,時至今日出現了像 Google、Yahoo!、Amazon 等等網路巨獸,這些大公司有能力去購買數以萬計的伺服器,並且把這些電腦串起來,成為一個龐大的運算資源。而龐大的運算資源自然就意味者更為多樣化和以前無法提供的新服務。所有的人現在可以在網路上不同的地方,利用各大企業開放出來的運算資源,進行資料的運算或是提供服務給使用者,於是就在這樣的情況之下,cloud computing 被提了出來。因為現在無論是一般的使用者或是開發者,都透過網路來取得資料或是進行資料運算,自己本地端的運算資源雖然有限,還是可以透過網路進行複雜的運算,結果資料就像是從天上的雲端掉下來一樣,相信學資訊的讀者都對於將網際網路表示成一朵雲的圖示不會陌生。例如下圖:

所以在我看來,cloud computing 並不代表任何單一技術的突破或是革新,它代表的是分散式運算本身的一種成熟,就好像我們看到網路發展到一定程度了,就有人喊出了 Web 2.0,都是一樣的道理。
分享至PLURK 噗浪
分享至FACEBOOK 臉書
前一陣子在新聞上看到不少有關於 Cloud Computing (雲端運算) 的報導,不過看看台灣的報導似乎都不是相當深入或是明確,於是我興起了寫這一篇文章的念頭。這篇文章是我自己對於雲端運算的理解,還希望各位讀者能一起參與討論,提供不同的見解。有機會的話,我也希望之後能夠繼續寫一些有關雲端運算中所包含的粗淺的技術介紹。
好吧,開門見山:雲端運算不是技術,它是概念。為什麼這樣說呢?因為 cloud computing 本身並不代表任何一項資訊科技的技術,它是一種電腦運算的概念,而一種概念就會有許多不同的方式去實踐,這個時候才會有不同的技術衍伸出來。就好像我們聽過 pervasive computing、ubiquitous computing、parallel computing 一樣,這些都是運算的概念,不是單指一項特定的技術。cloud computing 也不例外,它本質上就是代表分散式運算 (distributed computing) 的概念。而分散式運算說穿了,就是讓一些不同的電腦同時去幫你做事情、進行運算,所以你有兩台電腦也好、十萬台電腦也好,只要你有超過一台電腦,而且讓他們可以互相溝通,一起同時幫你做事情,恭喜你,這就是分散式運算。
好吧,如果雲端運算不過就是分散式運算罷了,故事就這樣結束也太沒意思了。那我們就繼續從其他名詞的出現繼續看下去好了。
大家可能同時也聽過 grid computing (網格運算) 這個名詞,相信滿多人覺得網格運算跟 cloud computing 很像。其實 cloud computing 在概念上跟 grid computing 並沒有非常嚴格的區隔或是很大的不同,兩者均可看成是 distributed computing (分散式運算) 衍伸出來的概念。grid computing 一詞出現得較早,將重點的概念放在異質系統之間運算資源的整合,簡單來說,就是讓不同等級的電腦、或是不同作業系統的電腦,彼此之間可以透過通訊標準來互相溝通,分享彼此的運算資源。在網際網路還沒有今天這麼發達之前,企業採用 grid computing,很大的原因是為了讓組織內部的 IT 資源達到更良好的使用率。
當大家努力去實現這樣的一個概念時,其實就促成了網際網路的蓬勃發展,因為網路本身就是在強調不同電腦之間的溝通以及合作,於是在各項基礎設施包括頻寬、通訊標準、電腦運算能力以及運算架構都逐漸發展成熟之後,提供給開發者或是一般使用者的網路服務便開始出現,這些網路服務 (Web Service) 提供給使用者簡單的介面來存取一些資源。當然一開始的時候,企業提供出來的,都是一些相當陽春的網路服務。
這些 Web Service 繼續發展下去,時至今日出現了像 Google、Yahoo!、Amazon 等等網路巨獸,這些大公司有能力去購買數以萬計的伺服器,並且把這些電腦串起來,成為一個龐大的運算資源。而龐大的運算資源自然就意味者更為多樣化和以前無法提供的新服務。所有的人現在可以在網路上不同的地方,利用各大企業開放出來的運算資源,進行資料的運算或是提供服務給使用者,於是就在這樣的情況之下,cloud computing 被提了出來。因為現在無論是一般的使用者或是開發者,都透過網路來取得資料或是進行資料運算,自己本地端的運算資源雖然有限,還是可以透過網路進行複雜的運算,結果資料就像是從天上的雲端掉下來一樣,相信學資訊的讀者都對於將網際網路表示成一朵雲的圖示不會陌生。例如下圖:
所以在我看來,cloud computing 並不代表任何單一技術的突破或是革新,它代表的是分散式運算本身的一種成熟,就好像我們看到網路發展到一定程度了,就有人喊出了 Web 2.0,都是一樣的道理。
Google雲端運算計畫 來台找創意
新聞辭典》雲端運算
【經濟日報╱記者何佩儒)】 2008.01.30 04:06 am
雲端運算(Cloud Computing)是Google為了處理成千上萬、散見全球各地的個人電腦與伺服器資料,所開發的運算模式,由於Google的企業精神是開放,Google也是透過開放原始碼的模式讓各界運用。
舉例來說,當網友登入Google的帳號及密碼,全球有數百台的電腦會同時運作,在很短的時間內確認資料。這些龐大的網路資料,密密麻麻交錯如同天上的雲一般,雲端運算的模式,就是要讓開發者學會同時讓數百台、數千台電腦運作,提高其運算的速度。
目前美國就有一些新創網站,開發出有創意的服務,由於運用雲端運算,可以服務眾多甚至跨國的使用者,但這些新創網站資金不足以購買許多伺服器,因此衍生出租用伺服器的生意。
雲端運算 網路服務超強超快
【聯合報╱許韶芹】 2008.01.30 08:56 am
雲端運算(cloud computing)最基本的概念,是將龐大的運算作業拆成千百個較小的作業,交給遠端、多台伺服器同時運算。透過這項技術,網路服務提供者可以在數秒之內,處理數以千計、萬計的資訊,並提供和「超級電腦」一樣強大效能的網路服務,以符合眾多網友的需求。
Google搜尋服務、Gmail、YouTube、Google Docs、Google Talk、iGoogle、Google Calendar都充分應用到這項技術。如今Google也秉著開放精神,要將這項技術的開放原始碼軟體和學術界分享。
雲端運算技術在網路服務中隨處可見,例如網路信箱,使用者擁有的大量電子郵件資料不是儲存在個人電腦中,而是儲存在眾多伺服器裡。
還有網路業者提供線上試算表,網友們可以在網路上輸入數值,計算工作也都是靠多台遠端電腦共同運算達成。
未來將進入「資訊離開個人電腦的時代」,如手機、GPS等行動裝置都可以透過雲端運算技術,開發出更多創新服務。
雲端運算不僅廣受資訊業者應用,在生物科學上也普遍被應用,例如分析DNA結構、基因圖譜定序、解析癌症細胞等,透過多台遠端電腦進行運算,比單單使用自己的單機運算,實在是快多了。
Google雲端運算計畫 來台找創意
【聯合報╱記者許韶芹/台北報導】 2008.01.30 04:06 am
全球搜尋引擎龍頭Google昨天宣布,將和台灣大學、交通大學合作推廣「雲端運算學術計畫」,幫助台灣學子學習這項網路開發主流技術。台灣是Google在美國本土外,第一個可望輸出快速運算模式的國家,有助台灣開發更多有創意的網路服務。
Google台灣工程研究所所長簡立峰說,網路資料日漸增多且龐雜,Google開發所謂「雲端運算」(cloud computing)的模式,可讓數百台、數千台電腦同時運作,這項運算概念充斥在日常生活各種網路服務中。
舉例來說,當網友登入Google的帳號及密碼,全球有數百台的電腦會同時運作,幾秒內即能確認。而且上千封郵件不是放在用戶的個人電腦裡,而是儲放在世界各地的伺服器中,這些伺服器就像一朵朵的雲,使用者不知道自己的郵件躲在哪朵雲中。
他表示,在Google搜尋關鍵字,可在不到一秒時間,搜尋出超過十億個網頁,這也和雲端運算有關,原理是將龐大運算作業拆成千百個較小的作業,在多部伺服器上同時動作。Google其他線上服務如Google Docs、Google Talk、iGoogle、Google Calendar都充分應用到這項技術。
他說,只要運算功能是在遠端、多部伺服器進行,本機只負責單純操作的技術,都可以稱為雲端運算。不只Google靠雲端運算起家,Yahoo!、Amazon、微軟也都採用這項技術提升網路服務功能。微軟創辦人比爾蓋茲曾說,未來是雲端運算的時代。
去年十月Google先在美國麻省理工學院、史丹佛、柏克萊加大、卡內基梅隆、馬里蘭和西雅圖華盛頓大學首度推廣,成效不錯。華盛頓大學學生甚至因此編寫出可掃描內容龐大的維基百科,以辨識垃圾條目程式,及根據地理位置編排全球新聞標題。
台灣是這項計畫的第二站,也是Google在美國本土以外的第一站。Google軟體工程師葉平說,Google將提供教材給台灣教授,並協助學校在現有運算資源上建置相關軟體系統,台灣Google還會派六名工程師到大學當學生的小師父。
目前Google已計畫和台大劉邦鋒教授開設的「平行運算」,以及交大教授彭文志和黃俊龍的「Web Services and Application」課程合作。
分享至PLURK 噗浪
分享至FACEBOOK 臉書
【經濟日報╱記者何佩儒)】 2008.01.30 04:06 am
雲端運算(Cloud Computing)是Google為了處理成千上萬、散見全球各地的個人電腦與伺服器資料,所開發的運算模式,由於Google的企業精神是開放,Google也是透過開放原始碼的模式讓各界運用。
舉例來說,當網友登入Google的帳號及密碼,全球有數百台的電腦會同時運作,在很短的時間內確認資料。這些龐大的網路資料,密密麻麻交錯如同天上的雲一般,雲端運算的模式,就是要讓開發者學會同時讓數百台、數千台電腦運作,提高其運算的速度。
目前美國就有一些新創網站,開發出有創意的服務,由於運用雲端運算,可以服務眾多甚至跨國的使用者,但這些新創網站資金不足以購買許多伺服器,因此衍生出租用伺服器的生意。
雲端運算 網路服務超強超快
【聯合報╱許韶芹】 2008.01.30 08:56 am
雲端運算(cloud computing)最基本的概念,是將龐大的運算作業拆成千百個較小的作業,交給遠端、多台伺服器同時運算。透過這項技術,網路服務提供者可以在數秒之內,處理數以千計、萬計的資訊,並提供和「超級電腦」一樣強大效能的網路服務,以符合眾多網友的需求。
Google搜尋服務、Gmail、YouTube、Google Docs、Google Talk、iGoogle、Google Calendar都充分應用到這項技術。如今Google也秉著開放精神,要將這項技術的開放原始碼軟體和學術界分享。
雲端運算技術在網路服務中隨處可見,例如網路信箱,使用者擁有的大量電子郵件資料不是儲存在個人電腦中,而是儲存在眾多伺服器裡。
還有網路業者提供線上試算表,網友們可以在網路上輸入數值,計算工作也都是靠多台遠端電腦共同運算達成。
未來將進入「資訊離開個人電腦的時代」,如手機、GPS等行動裝置都可以透過雲端運算技術,開發出更多創新服務。
雲端運算不僅廣受資訊業者應用,在生物科學上也普遍被應用,例如分析DNA結構、基因圖譜定序、解析癌症細胞等,透過多台遠端電腦進行運算,比單單使用自己的單機運算,實在是快多了。
Google雲端運算計畫 來台找創意
【聯合報╱記者許韶芹/台北報導】 2008.01.30 04:06 am
全球搜尋引擎龍頭Google昨天宣布,將和台灣大學、交通大學合作推廣「雲端運算學術計畫」,幫助台灣學子學習這項網路開發主流技術。台灣是Google在美國本土外,第一個可望輸出快速運算模式的國家,有助台灣開發更多有創意的網路服務。
Google台灣工程研究所所長簡立峰說,網路資料日漸增多且龐雜,Google開發所謂「雲端運算」(cloud computing)的模式,可讓數百台、數千台電腦同時運作,這項運算概念充斥在日常生活各種網路服務中。
舉例來說,當網友登入Google的帳號及密碼,全球有數百台的電腦會同時運作,幾秒內即能確認。而且上千封郵件不是放在用戶的個人電腦裡,而是儲放在世界各地的伺服器中,這些伺服器就像一朵朵的雲,使用者不知道自己的郵件躲在哪朵雲中。
他表示,在Google搜尋關鍵字,可在不到一秒時間,搜尋出超過十億個網頁,這也和雲端運算有關,原理是將龐大運算作業拆成千百個較小的作業,在多部伺服器上同時動作。Google其他線上服務如Google Docs、Google Talk、iGoogle、Google Calendar都充分應用到這項技術。
他說,只要運算功能是在遠端、多部伺服器進行,本機只負責單純操作的技術,都可以稱為雲端運算。不只Google靠雲端運算起家,Yahoo!、Amazon、微軟也都採用這項技術提升網路服務功能。微軟創辦人比爾蓋茲曾說,未來是雲端運算的時代。
去年十月Google先在美國麻省理工學院、史丹佛、柏克萊加大、卡內基梅隆、馬里蘭和西雅圖華盛頓大學首度推廣,成效不錯。華盛頓大學學生甚至因此編寫出可掃描內容龐大的維基百科,以辨識垃圾條目程式,及根據地理位置編排全球新聞標題。
台灣是這項計畫的第二站,也是Google在美國本土以外的第一站。Google軟體工程師葉平說,Google將提供教材給台灣教授,並協助學校在現有運算資源上建置相關軟體系統,台灣Google還會派六名工程師到大學當學生的小師父。
目前Google已計畫和台大劉邦鋒教授開設的「平行運算」,以及交大教授彭文志和黃俊龍的「Web Services and Application」課程合作。
2008年2月17日 星期日
[情報] ip1880單獨使用黑色匣列印!
可以用印表機維護軟體將IP120O也刷成IP2200,同樣,IP1880也可以刷成IP1180,也可以只裝一個彩色墨匣就列印。
A、下載佳能IP1180、IP1880、IP2580維修軟體。請點我下載
 D、點擊「Device ID」,如果右面方框內會顯示IP1800印表機訊息,說明已與IP1800連接(圖二)。
D、點擊「Device ID」,如果右面方框內會顯示IP1800印表機訊息,說明已與IP1800連接(圖二)。

 F、最後一步,關閉印表機再重新啟動,如果電腦沒有安裝IP1100或IP2580驅動程式,會顯示「發現新硬體」,若已安裝驅動那就可以體驗下IP1880單黑色墨匣也能列印。【 註:佳能IP1180、IP1880、IP2580,印表機軟體中也稱為IP1100、IP1800、IP2500。】
F、最後一步,關閉印表機再重新啟動,如果電腦沒有安裝IP1100或IP2580驅動程式,會顯示「發現新硬體」,若已安裝驅動那就可以體驗下IP1880單黑色墨匣也能列印。【 註:佳能IP1180、IP1880、IP2580,印表機軟體中也稱為IP1100、IP1800、IP2500。】
A、下載佳能IP1180、IP1880、IP2580維修軟體。請點我下載
B、IP1880印表機在待機狀態下並與電腦連接。
C、打開運行維修軟件。
C、打開運行維修軟件。
D、點擊「Device ID」,如果右面方框內會顯示IP1800印表機訊息,說明已與IP1800連接(圖二)。
F、最後一步,關閉印表機再重新啟動,如果電腦沒有安裝IP1100或IP2580驅動程式,會顯示「發現新硬體」,若已安裝驅動那就可以體驗下IP1880單黑色墨匣也能列印。【 註:佳能IP1180、IP1880、IP2580,印表機軟體中也稱為IP1100、IP1800、IP2500。】2008年2月16日 星期六
員工分紅費用化改變台廠遊戲規則 日月光營業利益率跌破20%
台灣上市櫃電子公司2008年起開始實施員工分紅費用化,影響所及,公司毛利率和營益率將遭到侵蝕。以封測業龍頭廠而言,日月光2008年首季營益率恐僅14~16%左右,與美國競爭對手艾克爾(Amkor)的13~15%水準接近;矽品首季營業利益率也將跌破20%關卡。業界人士認為,在考量員工分紅費用化提列之後,勢必將重新評估封測大廠的股票價值。
過去台灣封測廠的營運表現均優於國外大廠,不僅是在營收成長力道,在成本和費用控制管理相對良好,使得台廠在毛利率和營益率等獲利能力項目皆表現突出。不過,在台灣2008年開始實施員工分紅費用化之後,台廠在毛利率和營益率的優勢大幅減少,從日月光和矽品第1季展望預估(guidance)就看得出來。
矽品董事長林文伯預估第1季營收將比上季衰退10~13%,營益率將從2007年第4季23.9%降到17~19%。林文伯解釋,將員工分紅費用化列入財報之後,依矽品公司章程規定,員工分紅佔可分配盈餘的10%,這部分對營業利益影響約9%。此外,為了留住人才,矽品亦另將提撥營業利益的5%作為績效獎金,績效獎金與員工分紅合計對營業利益的影響約14%,若以營益率20%為例,則員工分紅與績效獎金估列進來後,營益率將被侵蝕掉2.8個百分點。
日月光財務長董宏思先前亦曾提及,員工分紅佔可分配盈餘的9%,對營業毛利的影響是1.2~1.3%。他預估首季毛利率將自上季的32.3%滑落至25~26%之間,除了營收下滑因素之外,員工分紅也是影響原因之一。通常員工分紅對毛利率的影響程度較小,多來自直接人員即生產線作業員的紅利,其餘大部分員工的分紅皆認列在費用項目上,如此一來,日月光2008年費用率勢必高於過去平均的9~10%水準,營益率遭壓縮的情況將較以往更為明顯。
以首季而言,日月光單季營益率可能落在14~16%之間。至於競爭對手艾克爾的費用率普遍在10~11%之間,換算首季營益率介於13~15%,兩家公司的營益率水準益趨接近,顯示日月光在本業獲利能力將與艾克爾相當。至於矽品首季營益率跌破20%,即使在未來營收成長下,由於矽品費用控管已十分嚴謹,未來營益率要想在回到過去25%以上的佳績恐須加把勁。
由於台系封測廠獲利能力改變,因此市場重新評估日月光和矽品的股票價值。業界人士認為,預料短期不是日月光和矽品市值下修,就是艾克爾上調,這點值得觀察。但長期而言,在考量費用化之後,雖然過去既有的稅賦優勢不再,台廠和國外廠商的競爭在同一起跑點上,以股票評價而言,有利於台股的本益比向美國靠攏。目前美股本益比均在20倍以上,台股不到10倍者比比皆是,長期而言,台灣科技股價也具有向上提升的機會。

分享至PLURK 噗浪
分享至FACEBOOK 臉書
過去台灣封測廠的營運表現均優於國外大廠,不僅是在營收成長力道,在成本和費用控制管理相對良好,使得台廠在毛利率和營益率等獲利能力項目皆表現突出。不過,在台灣2008年開始實施員工分紅費用化之後,台廠在毛利率和營益率的優勢大幅減少,從日月光和矽品第1季展望預估(guidance)就看得出來。
矽品董事長林文伯預估第1季營收將比上季衰退10~13%,營益率將從2007年第4季23.9%降到17~19%。林文伯解釋,將員工分紅費用化列入財報之後,依矽品公司章程規定,員工分紅佔可分配盈餘的10%,這部分對營業利益影響約9%。此外,為了留住人才,矽品亦另將提撥營業利益的5%作為績效獎金,績效獎金與員工分紅合計對營業利益的影響約14%,若以營益率20%為例,則員工分紅與績效獎金估列進來後,營益率將被侵蝕掉2.8個百分點。
日月光財務長董宏思先前亦曾提及,員工分紅佔可分配盈餘的9%,對營業毛利的影響是1.2~1.3%。他預估首季毛利率將自上季的32.3%滑落至25~26%之間,除了營收下滑因素之外,員工分紅也是影響原因之一。通常員工分紅對毛利率的影響程度較小,多來自直接人員即生產線作業員的紅利,其餘大部分員工的分紅皆認列在費用項目上,如此一來,日月光2008年費用率勢必高於過去平均的9~10%水準,營益率遭壓縮的情況將較以往更為明顯。
以首季而言,日月光單季營益率可能落在14~16%之間。至於競爭對手艾克爾的費用率普遍在10~11%之間,換算首季營益率介於13~15%,兩家公司的營益率水準益趨接近,顯示日月光在本業獲利能力將與艾克爾相當。至於矽品首季營益率跌破20%,即使在未來營收成長下,由於矽品費用控管已十分嚴謹,未來營益率要想在回到過去25%以上的佳績恐須加把勁。
由於台系封測廠獲利能力改變,因此市場重新評估日月光和矽品的股票價值。業界人士認為,預料短期不是日月光和矽品市值下修,就是艾克爾上調,這點值得觀察。但長期而言,在考量費用化之後,雖然過去既有的稅賦優勢不再,台廠和國外廠商的競爭在同一起跑點上,以股票評價而言,有利於台股的本益比向美國靠攏。目前美股本益比均在20倍以上,台股不到10倍者比比皆是,長期而言,台灣科技股價也具有向上提升的機會。

2008年2月13日 星期三
宏碁多品牌策略 2008年正式起跑
宏碁集團董事長王振堂新春喊話,歸納3大年度新方向,包含正式前進東瀛、輕薄小尺寸PC最快第2季上市,並決定將桌上型電腦(DT)事業全球操盤權交由捷威團隊負責;宏碁多品牌策略,2008年正式起跑。 另外,宏碁也首次在新春期間公布自結年度營收,2007年合併營收約新台幣4,617億元,年成長率達25%,稅後盈餘約129億元,年成長率達20.93% ,EPS約5.4元。
王振堂指出,2008年是宏碁前進日本市場的發動年,已談好通路市場的合作約定,認為不少品牌退守市場,反而是宏碁切入的時間點。王振堂強調,宏碁的競爭優勢是數量,預期2008年日本市場筆記型腦(NB)將有千萬台的規模,如果打得進日本,宏碁亞太市場的成長幅度將十分驚人。
事實上,宏碁所購併的捷威原本就有電腦產品在日本市場銷售,市調機構IDC第4季資料中,捷威在日本PC市場佔有率排名第10位,該季出貨量約6.2萬台(DT佔3.4萬台),與第9位的Panasonic的6.3萬台幾乎齊名。
此外,宏碁2008年也將更積極前進大陸、印度市場,2007年上半由於新設計款家用杜比Aspire、商用TravelMate產品線缺貨問題較嚴重,為站穩歐洲及美洲市場而迫使大陸市場先退出戰局,供貨也較不平均,但2008年整體產品線完整,大陸、印度等地數量將有相當幅度的成長。
至於小尺寸簡易型PC的布局,王振堂指出第2~3季之間會上市,而在「低價」、「超輕薄」2大優勢訴求部分宏碁會較重視超輕薄。王振堂強調,宏碁主要產品線流量大,目前最大挑戰在如何避免超輕薄新產品會侵蝕原本產品市場。
王振堂指出,2008年對DT將有更高期許,在評估捷威對DT有較強的研發與市場經驗後,決定會由捷威DT電腦部門成為集團全球DT操盤手。王振堂笑稱,宏碁不是只會在市場上以購併提振市佔成績,更重要的是吸取、重要相關經驗的人才進場,而捷威原有的產品線成績雖然不再對外公布,但已研擬總體優勢策略,作好打團體戰的準備。
宏碁集團之營收包含美國子公司捷威約2個半月之營收,但仍未含Packard Bell子公司營收,預計在2月底以前,Packard Bell的營收應該就可以併入宏碁集團營收當中。
王振堂表示,一般宏碁4月及11月都會舉辦法說會向外界提出財報成績,由於4月或許市場會更關注第1季集團表現,屆時才公布去年全年報略顯過時,這次自結數字會成為未來慣例,未來每年年初就會先公布自結年報數字,供市場參考。
展望2008年個人電腦產業前景,宏碁表示審慎樂觀,預期宏碁全年NB出貨量將較2007年成長40%;整體個人電腦出貨量,則預估亦較2007年成長30~35%。
王振堂指出,經濟景氣並不是相當明朗,而大環境經濟放緩,宏碁也會在這段時間以調整組織為主要營運計畫,產品的研發與設計也會進一步更全球化,而組織調整將走向精簡、更有效率的布局,言下之意裁員動作不可避免,王振堂也承認,這與2007年預設要讓捷威獨立運作的布局有所不同。
宏碁集團在春節前已經先發動第1波裁員,資遣約140名原捷威員工,包含10月出售捷威商用部門予MPC電腦公司後留下的員工。

分享至PLURK 噗浪
分享至FACEBOOK 臉書
王振堂指出,2008年是宏碁前進日本市場的發動年,已談好通路市場的合作約定,認為不少品牌退守市場,反而是宏碁切入的時間點。王振堂強調,宏碁的競爭優勢是數量,預期2008年日本市場筆記型腦(NB)將有千萬台的規模,如果打得進日本,宏碁亞太市場的成長幅度將十分驚人。
事實上,宏碁所購併的捷威原本就有電腦產品在日本市場銷售,市調機構IDC第4季資料中,捷威在日本PC市場佔有率排名第10位,該季出貨量約6.2萬台(DT佔3.4萬台),與第9位的Panasonic的6.3萬台幾乎齊名。
此外,宏碁2008年也將更積極前進大陸、印度市場,2007年上半由於新設計款家用杜比Aspire、商用TravelMate產品線缺貨問題較嚴重,為站穩歐洲及美洲市場而迫使大陸市場先退出戰局,供貨也較不平均,但2008年整體產品線完整,大陸、印度等地數量將有相當幅度的成長。
至於小尺寸簡易型PC的布局,王振堂指出第2~3季之間會上市,而在「低價」、「超輕薄」2大優勢訴求部分宏碁會較重視超輕薄。王振堂強調,宏碁主要產品線流量大,目前最大挑戰在如何避免超輕薄新產品會侵蝕原本產品市場。
王振堂指出,2008年對DT將有更高期許,在評估捷威對DT有較強的研發與市場經驗後,決定會由捷威DT電腦部門成為集團全球DT操盤手。王振堂笑稱,宏碁不是只會在市場上以購併提振市佔成績,更重要的是吸取、重要相關經驗的人才進場,而捷威原有的產品線成績雖然不再對外公布,但已研擬總體優勢策略,作好打團體戰的準備。
宏碁集團之營收包含美國子公司捷威約2個半月之營收,但仍未含Packard Bell子公司營收,預計在2月底以前,Packard Bell的營收應該就可以併入宏碁集團營收當中。
王振堂表示,一般宏碁4月及11月都會舉辦法說會向外界提出財報成績,由於4月或許市場會更關注第1季集團表現,屆時才公布去年全年報略顯過時,這次自結數字會成為未來慣例,未來每年年初就會先公布自結年報數字,供市場參考。
展望2008年個人電腦產業前景,宏碁表示審慎樂觀,預期宏碁全年NB出貨量將較2007年成長40%;整體個人電腦出貨量,則預估亦較2007年成長30~35%。
王振堂指出,經濟景氣並不是相當明朗,而大環境經濟放緩,宏碁也會在這段時間以調整組織為主要營運計畫,產品的研發與設計也會進一步更全球化,而組織調整將走向精簡、更有效率的布局,言下之意裁員動作不可避免,王振堂也承認,這與2007年預設要讓捷威獨立運作的布局有所不同。
宏碁集團在春節前已經先發動第1波裁員,資遣約140名原捷威員工,包含10月出售捷威商用部門予MPC電腦公司後留下的員工。

2008年2月10日 星期日
微軟搶下雅虎 擔心Google奪走金飯碗?
雅虎營運步履蹣跚已經不是一天兩天的事了,執行長Terry Semel下台、創辦人楊致遠在2007年6月底回鍋擔任執行長,試圖力挽狂瀾,進入2008年以來,投資人對於雅虎近半年來的營運表現,令人失望,再度引來要求執行長下台的呼聲四起,而就在這個雅虎動盪不安的時刻裡,微軟突如其來公開宣布將以每股31美元高價收購雅虎,PC時代的霸主微軟,進入到網路時代後,遇上了Google這個強敵,在獨力耕耘線上事業未果之後,策略大轉折以高價收購雅虎,挑戰Google。
開價慷慨 雅虎投資人心動
微軟提供以現金或換股收購雅虎的提議,顯然讓雅虎的投資人樂不可支,2月1日雅虎股價聞訊大漲,從前1日收盤價每股19.18美元,大漲9.17美元,單日漲幅高達47.8%,收盤價為28.35美元。事實上,2008年1月底到2月初的這幾天,簡直讓雅虎投資人洗了一場三溫暖。
雅虎甫於1月29日美股盤後,公布令投資人頭疼的財報,裁員、撙節成本等宣示,並未讓投資人信服,該公司股價在30日一開盤就跌到19美元以下,下探近4年來雅虎股價的新低點。不過,2月1日微軟在美股開盤前,主動提議溢價收購雅虎股票,終於也讓投資人能夠出脫手中低迷不振的股票,而雀躍不已。
跟據路透訪問許多投資法人的看法指出,若雅虎與微軟連姻不成,雅虎的股價很難在未來幾年內突破每股30美元價位,從投資人的立場看來,微軟這樁看來勢在必得的結親提議,開出的價格,其實相當慷慨。
微軟口袋深 收購雅虎勢在必得
截至2007年底,高科技業界擁有龐大現金的公司屈指可數。根據道瓊報導指出,微軟以高達210.8億美元現金居首位,蘋果則以184.5億美元現金居次,接下來則分別是英特爾與Google現金流各為153.6億美元及142.2億美元。
其中,包括微軟、蘋果及Google在內,皆無債務纏身,以此看來,微軟開價超過440億美元收購雅虎的提議,對微軟的財務狀況,並不至於產生重大衝擊,這也是微軟如此大方開價的緣由。
雖然雅虎也有過高達每股125美元的風光時刻,但不容置疑的是,目前的雅虎處境相當艱難,從2007年6月創辦人楊致遠回鍋擔任執行長,這半年多以來,雅虎還交不出令人滿意的成績單,而雅虎的股價始終在20美元左右徘徊,甚至還一度低於20美元價位。
對於微軟公開的求親提議,雅虎經營團隊已承諾盡快討論,然而,就算經營團隊不願公司易手,投資人極有可能以召開臨時股東大會的方式,讓雅虎不得不點頭這樁婚事。
微軟收購雅虎能否拼過Google?
事實上,微軟執行長Steven Ballmer對於收購雅虎的態度,也有180度大轉變。根據彭博資訊引述2006年Ballmer在法說會上,針對法人提問是否有意收購雅虎的問題時,Ballmer當時表示收購雅虎,並無法改善微軟的搜索業務,並表示微軟經營線上服務的策略是從無到有、獨力耕耘的。
不過,2008年2月1日Ballmer發出公開信給雅虎股東及公司員工,則徹底反轉了微軟歷來對於購併策略敬而遠之的方向,並表示收購雅虎是微軟轉型過程中,下一個重大的里程碑。這無疑是承認微軟過去在線上服務的經營,宣稱失敗。哈佛企管學院教授David B. Yoffie則指出,微軟過去不是沒有遇到過對手,但不管就規模、強度、獲利能力、能見度等,Google的表現在在讓微軟芒刺在背。
分析師指出,微軟光是改善其搜索運算及線上廣告軟體等,還不足以對付Google。的確,Google擁有令人印象深刻的科技,但Google也在搜尋引擎及線上廣告方面,享有著遠高於其他競爭對手的強勁成長動能。Google靠著在搜尋引擎的優勢,導入大量的瀏覽人次,連帶也吸引著更多的廣告商等,由此也帶來更高的人氣,這些優勢彼此強化,正是經濟學家稱為網路社群效應(network effects)的最佳例證。
其實,微軟對於網路社群效應的影響力,並不陌生,事實上,微軟正是在PC時代裡,運用網路社群效應淋漓盡致的玩家。微軟雖然在PC作業系統取得領先,但同時蘋果物件導向的作業系統也在同時競爭,但微軟在推出視窗作業系統後,鼓勵大量獨力軟體發展業者為視窗作業系統撰寫應用程式,彼此相生相容,也進而達到微軟視窗作業系統的全球支配力。
分析師認為,儘管過去幾年微軟的營運表現,依舊穩健成長,但投資人卻並不看好。從股價表現來看,微軟股價持續處於停滯不前的狀態。但事實上,微軟的營運表現依舊亮眼,光是Office部門的營收就高達48億美元,堪與Google整體營收媲美,而Office部門的營業利益更高達32億美元,亦即超過6成的獲利率,此外,Windows部門的獲利能力甚至更高。
儘管微軟在Office、Windows的獲利豐厚,但該公司的線上服務事業,卻始終瞠乎其後。以最近的1季財報結果來看,與Google高達48億美元營收相較,微軟的線上服務事業營收只有8.63億美元。即使合計雅虎與微軟的線上服務營收達26億美元,還是遠遠落在Google之後。
在華爾街投資人的眼中,微軟在網路時代的步伐,無疑是顯得步履蹣跚。分析師認為以超過440億美元的價格收購雅虎,對於想要拉近與Google距離的微軟而言,其實還是相當值得的。
不過,仍有分析師稱微軟收購雅虎的策略,是個在搖椅上構思出來的策略,雖然可以立刻擴大經濟規模,足以與Google一戰,但2公司整合之路恐怕相當艱辛。就品牌來看,雅虎與MSN這2個品牌,未來應該還是維持獨立經營,任何想要整合這2個品牌的努力,都可能得罪不少死忠使用者。
就線上廣告系統而言,雅虎有Panama,而微軟則有Adcenter與aQuantive,這些系統必須在有效率的合理條件下,進行整合,但若整合過程延宕,廣告主很可能另投Google,這也是微軟需冒風險之處。而在與Google決一死戰的搜索科技方面,過去雅虎與微軟皆投下了大量資金與時間,卻依然遠遠落後,2哥加上3哥能否勝過1哥?這個疑問,仍在大多數人心裡發酵。


分享至PLURK 噗浪
分享至FACEBOOK 臉書
開價慷慨 雅虎投資人心動
微軟提供以現金或換股收購雅虎的提議,顯然讓雅虎的投資人樂不可支,2月1日雅虎股價聞訊大漲,從前1日收盤價每股19.18美元,大漲9.17美元,單日漲幅高達47.8%,收盤價為28.35美元。事實上,2008年1月底到2月初的這幾天,簡直讓雅虎投資人洗了一場三溫暖。
雅虎甫於1月29日美股盤後,公布令投資人頭疼的財報,裁員、撙節成本等宣示,並未讓投資人信服,該公司股價在30日一開盤就跌到19美元以下,下探近4年來雅虎股價的新低點。不過,2月1日微軟在美股開盤前,主動提議溢價收購雅虎股票,終於也讓投資人能夠出脫手中低迷不振的股票,而雀躍不已。
跟據路透訪問許多投資法人的看法指出,若雅虎與微軟連姻不成,雅虎的股價很難在未來幾年內突破每股30美元價位,從投資人的立場看來,微軟這樁看來勢在必得的結親提議,開出的價格,其實相當慷慨。
微軟口袋深 收購雅虎勢在必得
截至2007年底,高科技業界擁有龐大現金的公司屈指可數。根據道瓊報導指出,微軟以高達210.8億美元現金居首位,蘋果則以184.5億美元現金居次,接下來則分別是英特爾與Google現金流各為153.6億美元及142.2億美元。
其中,包括微軟、蘋果及Google在內,皆無債務纏身,以此看來,微軟開價超過440億美元收購雅虎的提議,對微軟的財務狀況,並不至於產生重大衝擊,這也是微軟如此大方開價的緣由。
雖然雅虎也有過高達每股125美元的風光時刻,但不容置疑的是,目前的雅虎處境相當艱難,從2007年6月創辦人楊致遠回鍋擔任執行長,這半年多以來,雅虎還交不出令人滿意的成績單,而雅虎的股價始終在20美元左右徘徊,甚至還一度低於20美元價位。
對於微軟公開的求親提議,雅虎經營團隊已承諾盡快討論,然而,就算經營團隊不願公司易手,投資人極有可能以召開臨時股東大會的方式,讓雅虎不得不點頭這樁婚事。
微軟收購雅虎能否拼過Google?
事實上,微軟執行長Steven Ballmer對於收購雅虎的態度,也有180度大轉變。根據彭博資訊引述2006年Ballmer在法說會上,針對法人提問是否有意收購雅虎的問題時,Ballmer當時表示收購雅虎,並無法改善微軟的搜索業務,並表示微軟經營線上服務的策略是從無到有、獨力耕耘的。
不過,2008年2月1日Ballmer發出公開信給雅虎股東及公司員工,則徹底反轉了微軟歷來對於購併策略敬而遠之的方向,並表示收購雅虎是微軟轉型過程中,下一個重大的里程碑。這無疑是承認微軟過去在線上服務的經營,宣稱失敗。哈佛企管學院教授David B. Yoffie則指出,微軟過去不是沒有遇到過對手,但不管就規模、強度、獲利能力、能見度等,Google的表現在在讓微軟芒刺在背。
分析師指出,微軟光是改善其搜索運算及線上廣告軟體等,還不足以對付Google。的確,Google擁有令人印象深刻的科技,但Google也在搜尋引擎及線上廣告方面,享有著遠高於其他競爭對手的強勁成長動能。Google靠著在搜尋引擎的優勢,導入大量的瀏覽人次,連帶也吸引著更多的廣告商等,由此也帶來更高的人氣,這些優勢彼此強化,正是經濟學家稱為網路社群效應(network effects)的最佳例證。
其實,微軟對於網路社群效應的影響力,並不陌生,事實上,微軟正是在PC時代裡,運用網路社群效應淋漓盡致的玩家。微軟雖然在PC作業系統取得領先,但同時蘋果物件導向的作業系統也在同時競爭,但微軟在推出視窗作業系統後,鼓勵大量獨力軟體發展業者為視窗作業系統撰寫應用程式,彼此相生相容,也進而達到微軟視窗作業系統的全球支配力。
分析師認為,儘管過去幾年微軟的營運表現,依舊穩健成長,但投資人卻並不看好。從股價表現來看,微軟股價持續處於停滯不前的狀態。但事實上,微軟的營運表現依舊亮眼,光是Office部門的營收就高達48億美元,堪與Google整體營收媲美,而Office部門的營業利益更高達32億美元,亦即超過6成的獲利率,此外,Windows部門的獲利能力甚至更高。
儘管微軟在Office、Windows的獲利豐厚,但該公司的線上服務事業,卻始終瞠乎其後。以最近的1季財報結果來看,與Google高達48億美元營收相較,微軟的線上服務事業營收只有8.63億美元。即使合計雅虎與微軟的線上服務營收達26億美元,還是遠遠落在Google之後。
在華爾街投資人的眼中,微軟在網路時代的步伐,無疑是顯得步履蹣跚。分析師認為以超過440億美元的價格收購雅虎,對於想要拉近與Google距離的微軟而言,其實還是相當值得的。
不過,仍有分析師稱微軟收購雅虎的策略,是個在搖椅上構思出來的策略,雖然可以立刻擴大經濟規模,足以與Google一戰,但2公司整合之路恐怕相當艱辛。就品牌來看,雅虎與MSN這2個品牌,未來應該還是維持獨立經營,任何想要整合這2個品牌的努力,都可能得罪不少死忠使用者。
就線上廣告系統而言,雅虎有Panama,而微軟則有Adcenter與aQuantive,這些系統必須在有效率的合理條件下,進行整合,但若整合過程延宕,廣告主很可能另投Google,這也是微軟需冒風險之處。而在與Google決一死戰的搜索科技方面,過去雅虎與微軟皆投下了大量資金與時間,卻依然遠遠落後,2哥加上3哥能否勝過1哥?這個疑問,仍在大多數人心裡發酵。
藉由進階演算法 Web伺服器集群告別負載失衡窘態
明雲青/DIGITIMES
前言:當Web伺服器集群(Web Server Farm)的利用率出現傾斜(Skew)狀況時,便意謂著少數伺服器業已呈現應接不暇的現象,但在同一時刻,其他伺服器卻處於閒置的狀態,如此一來,用戶在不耐久候的前提下,即有可能心生埋怨,並對該系統的服務品質留下極為負面的印象;可以想見,絕大多數網路應用服務的提供者,都不樂見此事發生。
意欲避免Web伺服器集群負載不均,其實非輕而易舉之事,此乃由於,就本質而論,TCP/IP流量原本即呈現波浪走勢,甚難憑制式化的規則加以掌控,再者,隱含於每一條TCP Link背後的服務請求型態,也呈現著至為紊亂、多元化的走向,各個行為所對應到資源消耗需求,自然也不甚一致,在此情況下,倘若在Linux Virtual Server(LVS)環境之中,單憑系統核心裡頭IP負載平衡機制-IPVS所支援的制式演算法,恐難求取最佳平衡點,緣於此故,本文特就諸多相關技術文獻加以彙整、歸納,牽引出動態回饋式負載平衡(Dynamic-feedback Load Balancing)演算法,期望藉由該技術運用之道的闡述,協助用戶化解此一僵局。
在進入動態回饋式負載平衡演算法的議題之前,先就當前大多數Web運算環境的一些概況加以說明。此處必須強調的是,之所以採行動態回饋式負載平衡演算法,並非是將IPVS調度機制當中的所有演算法全都拋諸一旁,換言之,不同演算技術之間,並無相互取代關係,反倒會相輔相成。
以LVS集群環境而論,目前欲將所有來自於客戶端(Clinet)的服務請求,均衡地調度至集群當中的各台Web伺服器,基本上可從系統核心層面的IPVS出發,而IPVS目前所能支援的連結調度演算技術,包括循環式排程演算法(Round-Robin Scheduling)、加權循環式排程演算法(Weighted Round-Robin Scheduling)、最小連結數排程演算法(Least-Connection Scheduling)、加權最小連結數排程演算法(Weighted Least-Connection Scheduling)、基於位置最少連線排程演算法(Locality-Based Least-Connection Scheduling)、帶複製的基於位置最少連線排程演算法(Locality-Based Least Connections with Replication Scheduling)、目地雜湊排程演算法(Destination Hashing Scheduling),以及來源雜湊排程演算法(Source Hashing Scheduling)等共計8項,其中又以加權循環式排程、加權最小連結數排程等2項技術,被使用到的機率相對較大。
加權循環式、加權最小連結數等排程技術之介紹
所謂加權循環式排程演算法,旨在化解伺服器之間效能不一的狀況,主要是以相對應的權值,作為各台伺服器處理效能的表徵,一般而言,預設(Default)權值為1。
假使伺服器甲的權值為1,而伺服器乙的權值為2,即表示伺服器甲的處理效能,為乙的一半而已;論及加權循環式排程演算法,便是依照權值的高低,佐以循環排程的方式,從而將各個服務請求,分配至各台伺服器加以執行,而權值較高的伺服器,其所能處理的連結數目,將比權值較低的伺服器來得多,至於權值相同的伺服器,則可處理同等數目的連結數。
在介紹加權循環式排程演算法的進行流程之前,先進行前提假設:有1組Web伺服器集群Q = {Q0, Q1, Q2, …, Qn-1},此時即可以W(Qi)作為伺服器Qi的權值表徵,接著以i表示上一次選擇的伺服器,cw表示目前排程的權值,max(Q)表示Q伺服器集群當中所有伺服器的最大權值,qcd(Q)表示Q伺服器集群當中所有伺服器權值的最大公約數字,而變數i初始化數值為-1,cw初始化數值為0。如此一來,其流程大致如下圖示。

此外,探究每一客戶端的TCP連結行為,其背後都會植基於不同的服務請求,每個請求所需的處理時間、以及所需消耗的運算資源,由於變數甚多,舉凡請求服務的型態、當下的網路頻寬與伺服器資源利用情況,都有可能造成重大影響,故其結果往往多所迥異。
在此情況下,一些負載相對吃重的請求,由於需要進行較高密集的查詢,甚或需要造訪資料庫,故其回應速度難免相對遲緩;相反的,如果只需要進行簡單計算,抑或僅欲讀取1個HTML頁面,則回應速度便會相對來得快。
由此,系統管理員將不難理解,礙於各項請求被處理時程之巨大差異,即可能導致伺服器使用狀況的嚴重傾斜,亦即負載失衡狀態。在此舉個例子,假設1個Web頁面係由甲、乙、丙、丁等4個檔案所組合而成,而其間甲為大型圖像檔案,此時客戶端瀏覽器欲同時造訪此一網頁,即需要建立4個連結,同時對這4個檔案加以讀取,若僅有單一客戶端從事此項連結行為,或許還在控制範圍之內,但如果同一時間內,有許多客戶端都連結到該網頁,情況便將失控。
最糟的狀況是,所有攸關甲檔案的請求,將被分派到同一台伺服器,而該台伺服器的負載頓時飆高,甚至已經窮於應付,故有些請求貯列被拖得相當長,且還不停地接收到新的請求,但此時其他伺服器卻處於閒置狀態;值此時刻,便即Web集群內含再多伺服器,亦難營造出令前端用戶滿意的服務品質。
值得一提的是,前述這般失衡狀態,若是對應到常見的簡單連結調度方式,便可能會使得Web伺服器傾斜狀況更加顯著,假設用戶採行若採用循環式排程演算法,而且其伺服器集群係由4台伺服器所組合而成,則其間某1台伺服器,極可能總是接收到猶如前例甲檔案(大型圖像檔案)的請求,從而造成整體系統資源利用率的偏低,亦即4台伺服器負載不均的狀況。
啟用動態式回饋負載平衡 化解伺服器集群失衡現象
為解決前述種種亂象,用戶即不妨可考慮採用動態式回饋負載平衡演算法,來彌補簡單連結調度方式之不足,此乃由於,這項演算法有考慮到伺服器的即時負載與回應狀況,會就Web伺服器之間處理請求的比重,做出持續性的調整,據以避免部分伺服器遭逢超載狀況時,依然收到大量請求之現象,把工作任務均攤給集群中的其他成員,進而拉抬整體系統的吞吐效率。
茲以下列圖示,闡述動態式回饋負載平衡的工作環境。

在上圖當中,係於負載調度器之上,運行著Monitor Daemon進程,並由此項機制來負責監控與蒐集各台伺服器的負載資訊,此外還能夠依據多個負載資訊,計算出1個綜合性的負載值;換言之,當Monitor Daemon將各台伺服器的綜合負載值,以及當下的權值算出1組新的權值後,倘若發現新的權值與當前權值之間的差異,大於其所設定的Threshold數值,此時Monitor Daemon便會將該伺服器的權值,設置到系統核心裡頭的IPVS調度機制中。
持平而論,依TCP/IP流量的慣性而論,往往是由許多「短事務」搭配一些「長事務」所組合而成,不過長事務所挾帶的工作負載需求,通常會在整體工作量的結構中,佔有相當高的比例,如此一來,用戶便應採行1種較聰明的負載平衡演算法,方能避免來自於長事務的請求,總是被分派到特定主機來執行,換言之,便是把原本挾帶Burst意味的分布方式,調校成為具備相對勻稱的分布格局;值此時刻,所謂的動態回饋負載平衡演算法,便不失為用以控制新連結的任務分派、以及各台伺服器負載狀況的可行技術。
具體的作法是,假使在IPVS調度機制中,採行加權循環式排程演算法,用以針對新請求連結來進行排程,即可在負載調度器的用戶空間中,運行Monitor Daemon,並由它來定時監視與蒐集各台伺服器的負載資訊,從而根據多個負載資訊,算出1個綜合負載值,如同前面已提及的運作流程。
與此同時,當綜合負載值顯示出,伺服器處於負載吃重之際,則新計算出的權值,將比其當前權值來得小,如此一來,被新分派到該伺服器的請求數目,就會自動減少;相反的,如果綜合負載值顯示某台或某些伺服器,處在利用率偏低的狀態,則新計算出來的權值,自然就會比其當前權值要來得大,故系統即會針對該台或該群伺服器,增加新請求的接收數量排程。
另外,假使新權值與當前權值的差異,比原本設定的Threshold數值為大,則Monitor Daemon會將該伺服器的權值,設置到IPVS調度器之中,此後再度過了一定的時間間距後,Monitor Daemon即再度查詢各台伺服器的負載狀況,同時再就伺服器的權值進行相對應的調整,而且會循週期性模式反覆進行,究其終極目的,無非是讓伺服器集群得以維持較佳的利用率。
因此,在運行加權循環式排程演算法的狀態下,當伺服器的權值歸零之後,則其已建立的連結,仍將持續獲得該伺服器所提供之服務,但新的連結請求,就不會被排程至該伺服器;此時系統管理員也可考慮把其中1台伺服器的權值設定為0,讓該伺服器完完全全地安靜下來,當已有的連結都處理完畢後,就可以把該台伺服器予以切割,然後對其進行硬體升級或更新等維護事務,畢竟維護工作對於系統管理而言,著實為不可或缺的一環。
在此前提下,用戶若欲於動態式回饋負載平衡機制中,確保一些必要性的維護工作得以順利運行的話,則當伺服器的權值為0時,便不應對伺服器的權值進行任何調整。
而在動態式回饋負載平衡演算法的使用過程中,如前所述,有牽涉到綜合負載值的計算,有關於這一數值的演算來源,主要係含括2種型態的負載資訊,一為輸入指標,另一則是伺服器指標;其中輸入指標必須由調度器上加以蒐集,至於伺服器指標,則代表存在於伺服器之上的各項負載資訊。值得一提的,採行綜合負載的計算方式,主要理由是為了讓伺服器當前的負載狀況,獲得相對精準的反映,而不同的應用程式運行基礎之上,連帶也將產生不同程度的負載狀態。
如此一來,藉由各項負載資訊係數的充分引用,即可適度地彰顯出各項負載資訊,處在綜合負載數值之中的輕重,從而俾使系統管理員,能根據不同應用服務的需求,調整各項負載資訊的係數,也讓系統管理員能更加方便地就蒐集負載資訊的時間間距部分,加以精確地設定。
所謂輸入指標,主要是在單位時間裡頭,伺服器所接收到新連結數目,佔整體平均連結數目的比重關係,是透過調度器加以蒐集而來,因此這一指標等同於伺服器負載狀況的估計值。假設伺服器Si,分別在T1、T2等時段,對應到調度器計數機制的數值為Ci1、Ci2,即可計算出Si伺服器在T2-T1時段內,其所接收到的新請求連結數為Ni = Ci2 - Ci1;如此一來,1組伺服器在T2-T1時段內伺服器Si所接收到新連結數為{Ni},而伺服器Si的輸入指標INPUTi便是其新連結數、與n台伺服器所接收之平均連結數目的比值,具體公式內容如下。

至於伺服器指標,則是用以記錄存在於各台伺服器的各項負載資訊,譬如代表伺服器當前處理器負載狀況的LOADi、代表伺服器當前磁碟使用狀況的Di、代表伺服器當前記憶體使用狀況的Mi,以及當前進程(Process)數目的Pi;有關於這些資訊,系統管理員可藉由2種途徑加以取得,其一,是從所有的伺服器上所運行的SNMP(Simple Network Management Protocol)服務進程來著手,繼而利用調度器上的Monitor Daemon、透過SNMP向各台伺服器進行查詢,以獲取這些資訊,另外,則是在伺服器上灌裝可負責蒐集這些資訊的代理程式,然後由代理程式定時地向Monitor Daemon回報負載資訊。
假設伺服器在設定的時間間距內,並未做出任何回應,則Monitor Daemon即會認為該伺服器已無力應付新增請求連結,從而在調度器裡頭,將該將伺服器的權值設置為0,讓它不會再繼續接收到新的排程;倘若在下一次資訊蒐集過程中,該伺服器又開始提出回應,則系統便將對其權值進行調整,然後再對這些資料進行處理,使其落在[0, ∞]的區間內,其中1代表負載處於恰到好處的狀態,小於1代表伺服器處於低負載狀況,大於1則代表伺服器處於超載狀況。
值得一提的,伺服器在提供各項應用服務所對應到的回應時間,也堪稱衡量伺服器指標的重要依據之一,因為它較能充分反映伺服器上請求等待佇列的長度,以及面對各個請求的處理時間;意欲蒐集此項數據,仍得透過調度器上的Monitor Daemon,作為客戶端訪問伺服器提供之服務所測得的回應時間;倘若伺服器在設定的時間間距未做出回應,則Monitor Daemon會認為該伺服器已不適合繼續執行任務,進而將該伺服器在調度器中的權值設置為0,如此一來,系統管理員便可依據回應時間進行調整,從而獲得RESPONSEi資訊。
在掌握了DISKi、MEMORYi、PROCESSi、RESPONSEi等數據後,系統管理員便可援引1組可供動態調整的係數-Ri,用以彰顯各項負載參數的重要程度,其中ΣRi = 1,而綜合負載即可藉由下列公式加以計算。當然,假設系統管理員發現到,當前的Ri係數已不能反映實際應用的負載狀況,便可針對該數值持續進行修正,直至取得1組貼近實際狀況的係數為止。

分享至PLURK 噗浪
分享至FACEBOOK 臉書
前言:當Web伺服器集群(Web Server Farm)的利用率出現傾斜(Skew)狀況時,便意謂著少數伺服器業已呈現應接不暇的現象,但在同一時刻,其他伺服器卻處於閒置的狀態,如此一來,用戶在不耐久候的前提下,即有可能心生埋怨,並對該系統的服務品質留下極為負面的印象;可以想見,絕大多數網路應用服務的提供者,都不樂見此事發生。
意欲避免Web伺服器集群負載不均,其實非輕而易舉之事,此乃由於,就本質而論,TCP/IP流量原本即呈現波浪走勢,甚難憑制式化的規則加以掌控,再者,隱含於每一條TCP Link背後的服務請求型態,也呈現著至為紊亂、多元化的走向,各個行為所對應到資源消耗需求,自然也不甚一致,在此情況下,倘若在Linux Virtual Server(LVS)環境之中,單憑系統核心裡頭IP負載平衡機制-IPVS所支援的制式演算法,恐難求取最佳平衡點,緣於此故,本文特就諸多相關技術文獻加以彙整、歸納,牽引出動態回饋式負載平衡(Dynamic-feedback Load Balancing)演算法,期望藉由該技術運用之道的闡述,協助用戶化解此一僵局。
在進入動態回饋式負載平衡演算法的議題之前,先就當前大多數Web運算環境的一些概況加以說明。此處必須強調的是,之所以採行動態回饋式負載平衡演算法,並非是將IPVS調度機制當中的所有演算法全都拋諸一旁,換言之,不同演算技術之間,並無相互取代關係,反倒會相輔相成。
以LVS集群環境而論,目前欲將所有來自於客戶端(Clinet)的服務請求,均衡地調度至集群當中的各台Web伺服器,基本上可從系統核心層面的IPVS出發,而IPVS目前所能支援的連結調度演算技術,包括循環式排程演算法(Round-Robin Scheduling)、加權循環式排程演算法(Weighted Round-Robin Scheduling)、最小連結數排程演算法(Least-Connection Scheduling)、加權最小連結數排程演算法(Weighted Least-Connection Scheduling)、基於位置最少連線排程演算法(Locality-Based Least-Connection Scheduling)、帶複製的基於位置最少連線排程演算法(Locality-Based Least Connections with Replication Scheduling)、目地雜湊排程演算法(Destination Hashing Scheduling),以及來源雜湊排程演算法(Source Hashing Scheduling)等共計8項,其中又以加權循環式排程、加權最小連結數排程等2項技術,被使用到的機率相對較大。
加權循環式、加權最小連結數等排程技術之介紹
所謂加權循環式排程演算法,旨在化解伺服器之間效能不一的狀況,主要是以相對應的權值,作為各台伺服器處理效能的表徵,一般而言,預設(Default)權值為1。
假使伺服器甲的權值為1,而伺服器乙的權值為2,即表示伺服器甲的處理效能,為乙的一半而已;論及加權循環式排程演算法,便是依照權值的高低,佐以循環排程的方式,從而將各個服務請求,分配至各台伺服器加以執行,而權值較高的伺服器,其所能處理的連結數目,將比權值較低的伺服器來得多,至於權值相同的伺服器,則可處理同等數目的連結數。
在介紹加權循環式排程演算法的進行流程之前,先進行前提假設:有1組Web伺服器集群Q = {Q0, Q1, Q2, …, Qn-1},此時即可以W(Qi)作為伺服器Qi的權值表徵,接著以i表示上一次選擇的伺服器,cw表示目前排程的權值,max(Q)表示Q伺服器集群當中所有伺服器的最大權值,qcd(Q)表示Q伺服器集群當中所有伺服器權值的最大公約數字,而變數i初始化數值為-1,cw初始化數值為0。如此一來,其流程大致如下圖示。
按上例流程,不難發現到,倘若伺服器權值為0的話,則該伺服器將不會被分派工作,因此,假使集群內所有伺服器的權值都是0、亦即W(Qi)=0,此時就無任何1台伺服器可被調用,那麼,演算法便會返回NULL,換言之,此後所有新增的連結,都將自動遭到拋棄。
至於加權最小連結數排程演算法,則意謂著最小連結排程的超集合,而各台伺服器皆以相對應的權值,表示其處理效能,Default權值仍為1,而企業系統管理員可以動態地針對伺服器的權值加以調整。
該演算技術在排程新連結之際,都將儘可能使伺服器的已建立連結數,與其權值成一定比例。而在進入加權最小連結數排程演算法的流程闡述之前,同樣先做一些前提假設:假設有1組Web伺服器集群Q = {Q0, Q1, Q2, …, Qn-1},W(Qi)作為伺服器Qi的權值表徵,C(Qi)代表伺服器Qi當下的連結數,而所有伺服器目前連結數目的總和為CSUM =ΣC(Qi)(i=0,1,2,3,…,n-1)。
當前新連結請求,將會被分配至伺服器Qm,而Qm必須能夠滿足下列條件。值得一提的是,W(Qi)不得為0。

只不過,除法計算所須耗用的處理器時脈環,通常會比乘法計算多出許多,而且Linux核心之中,除法計算也不被允許,在此前提下,伺服器的權值都會大於0,故原本所採行C(Qm)/ W(Qm)> C(Qi)/ W(Qi)之判斷條件,不妨可加以優化到下列結果,並同時保證當伺服器權值為0的話,該伺服器便不會進入排程。

歷經這一微幅調整後,加權最小連結數排程演算法的執行流程,便可被精簡到下列步驟。

Web連結請求迥異甚大 傾斜狀況在所難免
分析多數Web伺服器之所以出現負載失衡狀態,箇中原因其實不難理解。首先,論及TCP/IP流量的特徵,即充滿了濃厚的波浪型樣貌,亦即可能在一段較長時間的小流量後,便出現一段大流量連結請求的湧入,這波過後,或將回歸到小流量狀態,猶如週期性的波浪理論一般,在WAN世界如此,在LAN環境亦可套用此一原理,著實讓人捉摸不定;正因如此,本文才會以動態回饋式負載平衡演算技術為初衷,此乃由於,惟有透過該項演算法,方能讓伺服器集群,被動態調教成為「足以應付不定性的Web波浪」。
此外,探究每一客戶端的TCP連結行為,其背後都會植基於不同的服務請求,每個請求所需的處理時間、以及所需消耗的運算資源,由於變數甚多,舉凡請求服務的型態、當下的網路頻寬與伺服器資源利用情況,都有可能造成重大影響,故其結果往往多所迥異。
在此情況下,一些負載相對吃重的請求,由於需要進行較高密集的查詢,甚或需要造訪資料庫,故其回應速度難免相對遲緩;相反的,如果只需要進行簡單計算,抑或僅欲讀取1個HTML頁面,則回應速度便會相對來得快。
由此,系統管理員將不難理解,礙於各項請求被處理時程之巨大差異,即可能導致伺服器使用狀況的嚴重傾斜,亦即負載失衡狀態。在此舉個例子,假設1個Web頁面係由甲、乙、丙、丁等4個檔案所組合而成,而其間甲為大型圖像檔案,此時客戶端瀏覽器欲同時造訪此一網頁,即需要建立4個連結,同時對這4個檔案加以讀取,若僅有單一客戶端從事此項連結行為,或許還在控制範圍之內,但如果同一時間內,有許多客戶端都連結到該網頁,情況便將失控。
最糟的狀況是,所有攸關甲檔案的請求,將被分派到同一台伺服器,而該台伺服器的負載頓時飆高,甚至已經窮於應付,故有些請求貯列被拖得相當長,且還不停地接收到新的請求,但此時其他伺服器卻處於閒置狀態;值此時刻,便即Web集群內含再多伺服器,亦難營造出令前端用戶滿意的服務品質。
值得一提的是,前述這般失衡狀態,若是對應到常見的簡單連結調度方式,便可能會使得Web伺服器傾斜狀況更加顯著,假設用戶採行若採用循環式排程演算法,而且其伺服器集群係由4台伺服器所組合而成,則其間某1台伺服器,極可能總是接收到猶如前例甲檔案(大型圖像檔案)的請求,從而造成整體系統資源利用率的偏低,亦即4台伺服器負載不均的狀況。
啟用動態式回饋負載平衡 化解伺服器集群失衡現象
為解決前述種種亂象,用戶即不妨可考慮採用動態式回饋負載平衡演算法,來彌補簡單連結調度方式之不足,此乃由於,這項演算法有考慮到伺服器的即時負載與回應狀況,會就Web伺服器之間處理請求的比重,做出持續性的調整,據以避免部分伺服器遭逢超載狀況時,依然收到大量請求之現象,把工作任務均攤給集群中的其他成員,進而拉抬整體系統的吞吐效率。
茲以下列圖示,闡述動態式回饋負載平衡的工作環境。
在上圖當中,係於負載調度器之上,運行著Monitor Daemon進程,並由此項機制來負責監控與蒐集各台伺服器的負載資訊,此外還能夠依據多個負載資訊,計算出1個綜合性的負載值;換言之,當Monitor Daemon將各台伺服器的綜合負載值,以及當下的權值算出1組新的權值後,倘若發現新的權值與當前權值之間的差異,大於其所設定的Threshold數值,此時Monitor Daemon便會將該伺服器的權值,設置到系統核心裡頭的IPVS調度機制中。
持平而論,依TCP/IP流量的慣性而論,往往是由許多「短事務」搭配一些「長事務」所組合而成,不過長事務所挾帶的工作負載需求,通常會在整體工作量的結構中,佔有相當高的比例,如此一來,用戶便應採行1種較聰明的負載平衡演算法,方能避免來自於長事務的請求,總是被分派到特定主機來執行,換言之,便是把原本挾帶Burst意味的分布方式,調校成為具備相對勻稱的分布格局;值此時刻,所謂的動態回饋負載平衡演算法,便不失為用以控制新連結的任務分派、以及各台伺服器負載狀況的可行技術。
具體的作法是,假使在IPVS調度機制中,採行加權循環式排程演算法,用以針對新請求連結來進行排程,即可在負載調度器的用戶空間中,運行Monitor Daemon,並由它來定時監視與蒐集各台伺服器的負載資訊,從而根據多個負載資訊,算出1個綜合負載值,如同前面已提及的運作流程。
與此同時,當綜合負載值顯示出,伺服器處於負載吃重之際,則新計算出的權值,將比其當前權值來得小,如此一來,被新分派到該伺服器的請求數目,就會自動減少;相反的,如果綜合負載值顯示某台或某些伺服器,處在利用率偏低的狀態,則新計算出來的權值,自然就會比其當前權值要來得大,故系統即會針對該台或該群伺服器,增加新請求的接收數量排程。
另外,假使新權值與當前權值的差異,比原本設定的Threshold數值為大,則Monitor Daemon會將該伺服器的權值,設置到IPVS調度器之中,此後再度過了一定的時間間距後,Monitor Daemon即再度查詢各台伺服器的負載狀況,同時再就伺服器的權值進行相對應的調整,而且會循週期性模式反覆進行,究其終極目的,無非是讓伺服器集群得以維持較佳的利用率。
因此,在運行加權循環式排程演算法的狀態下,當伺服器的權值歸零之後,則其已建立的連結,仍將持續獲得該伺服器所提供之服務,但新的連結請求,就不會被排程至該伺服器;此時系統管理員也可考慮把其中1台伺服器的權值設定為0,讓該伺服器完完全全地安靜下來,當已有的連結都處理完畢後,就可以把該台伺服器予以切割,然後對其進行硬體升級或更新等維護事務,畢竟維護工作對於系統管理而言,著實為不可或缺的一環。
在此前提下,用戶若欲於動態式回饋負載平衡機制中,確保一些必要性的維護工作得以順利運行的話,則當伺服器的權值為0時,便不應對伺服器的權值進行任何調整。
而在動態式回饋負載平衡演算法的使用過程中,如前所述,有牽涉到綜合負載值的計算,有關於這一數值的演算來源,主要係含括2種型態的負載資訊,一為輸入指標,另一則是伺服器指標;其中輸入指標必須由調度器上加以蒐集,至於伺服器指標,則代表存在於伺服器之上的各項負載資訊。值得一提的,採行綜合負載的計算方式,主要理由是為了讓伺服器當前的負載狀況,獲得相對精準的反映,而不同的應用程式運行基礎之上,連帶也將產生不同程度的負載狀態。
如此一來,藉由各項負載資訊係數的充分引用,即可適度地彰顯出各項負載資訊,處在綜合負載數值之中的輕重,從而俾使系統管理員,能根據不同應用服務的需求,調整各項負載資訊的係數,也讓系統管理員能更加方便地就蒐集負載資訊的時間間距部分,加以精確地設定。
所謂輸入指標,主要是在單位時間裡頭,伺服器所接收到新連結數目,佔整體平均連結數目的比重關係,是透過調度器加以蒐集而來,因此這一指標等同於伺服器負載狀況的估計值。假設伺服器Si,分別在T1、T2等時段,對應到調度器計數機制的數值為Ci1、Ci2,即可計算出Si伺服器在T2-T1時段內,其所接收到的新請求連結數為Ni = Ci2 - Ci1;如此一來,1組伺服器在T2-T1時段內伺服器Si所接收到新連結數為{Ni},而伺服器Si的輸入指標INPUTi便是其新連結數、與n台伺服器所接收之平均連結數目的比值,具體公式內容如下。
至於伺服器指標,則是用以記錄存在於各台伺服器的各項負載資訊,譬如代表伺服器當前處理器負載狀況的LOADi、代表伺服器當前磁碟使用狀況的Di、代表伺服器當前記憶體使用狀況的Mi,以及當前進程(Process)數目的Pi;有關於這些資訊,系統管理員可藉由2種途徑加以取得,其一,是從所有的伺服器上所運行的SNMP(Simple Network Management Protocol)服務進程來著手,繼而利用調度器上的Monitor Daemon、透過SNMP向各台伺服器進行查詢,以獲取這些資訊,另外,則是在伺服器上灌裝可負責蒐集這些資訊的代理程式,然後由代理程式定時地向Monitor Daemon回報負載資訊。
假設伺服器在設定的時間間距內,並未做出任何回應,則Monitor Daemon即會認為該伺服器已無力應付新增請求連結,從而在調度器裡頭,將該將伺服器的權值設置為0,讓它不會再繼續接收到新的排程;倘若在下一次資訊蒐集過程中,該伺服器又開始提出回應,則系統便將對其權值進行調整,然後再對這些資料進行處理,使其落在[0, ∞]的區間內,其中1代表負載處於恰到好處的狀態,小於1代表伺服器處於低負載狀況,大於1則代表伺服器處於超載狀況。
值得一提的,伺服器在提供各項應用服務所對應到的回應時間,也堪稱衡量伺服器指標的重要依據之一,因為它較能充分反映伺服器上請求等待佇列的長度,以及面對各個請求的處理時間;意欲蒐集此項數據,仍得透過調度器上的Monitor Daemon,作為客戶端訪問伺服器提供之服務所測得的回應時間;倘若伺服器在設定的時間間距未做出回應,則Monitor Daemon會認為該伺服器已不適合繼續執行任務,進而將該伺服器在調度器中的權值設置為0,如此一來,系統管理員便可依據回應時間進行調整,從而獲得RESPONSEi資訊。
在掌握了DISKi、MEMORYi、PROCESSi、RESPONSEi等數據後,系統管理員便可援引1組可供動態調整的係數-Ri,用以彰顯各項負載參數的重要程度,其中ΣRi = 1,而綜合負載即可藉由下列公式加以計算。當然,假設系統管理員發現到,當前的Ri係數已不能反映實際應用的負載狀況,便可針對該數值持續進行修正,直至取得1組貼近實際狀況的係數為止。
另一方面,不可諱言,若把查詢時間的間隔設定得愈短,就能夠更精確地反映各台伺服器的負載狀況,然而太過密集的話,也容易為調度器、伺服器構成沈重負擔,因此務必在得失之間取得平衡,一般來說,時間間距設定在5∼20秒內,還算是合情合理,過猶不及、都不理想。
借助適當公式 精準計算負載權值
每當任何一台伺服器加入集群環境之際,系統管理員通常對其設定1個初始性的權值,往往以DEFAULT_WEIGHTi來表示,爾後,系統核心當中的IPVS調度機制,亦將優先採用此一權值;然伴隨著伺服器負載狀態的改變,又憑藉動態式回饋負載平衡演算法對其權值進行調整,如果不加以節制,仍有可能讓權值演變成龐大數值,與此同時,系統管理員即有必要針對權值範圍加以限制,可透過[DEFAULT_WEIGHTi, SCALE*DEFAULT_WEIGHTi]公式來實現其限制目的,至於公式中的SCALE,其Default值為10,但會隨時被調整。此後,在Monitor Daemon週期性地執行任務之下,如果DEFAULT_WEIGHTi不是0,而欲查詢該伺服器的各項負載參數,並計算綜合負載值AGGREGATE_LOADi的話,可藉由下列計算公式為之,其計算結果可作為系統管理員用以調整權值之依據。此處附帶說明,公式中的0.95,係表示系統管理員所期望的系統利用率,其中A的Default值為5,但可被動態調整,當綜合負載值等於0.95,伺服器權值也不會改變,但是當綜合負載值大於0.95時,伺服器權值則會變小。

假使新權值比SCALE*DEFAULT_WEIGHTi來得大,系統管理員可將新的權值設定為SCALE*DEFAULT_WEIGHTi,但若新權值與當前權值之間的差距大於原本所設定的Threshold值,便可將新權值設定到IPVS調度參數中,藉此讓權值得以被調整到相對穩定的狀況。
如此一來,當所有伺服器的權值,皆小於各自的DEFAULT_WEIGHT,則意謂全體伺服器集群處在超載狀態,此時有必要加入新的伺服器節點至集群之中,據以分攤繁重的計算任務;相反的,如果所有伺服器的權值都與SCALE*DEFAULT_WEIGHT甚為接近,則意謂當前系統的負載,皆處於相對清閒的狀態,此時較無排程方面的困擾。
附帶說明,Red Hat Enterprise Linux系統之中,有1個名為Piranha的集群管理工具選項(如下圖),其雖然只能涵蓋處理器負載狀況等少數面向,但也可協助系統管理員,用以執行1個簡易型的動態式回饋負載平衡計算,相關計算方式與前述公式頗為神似,就某種程度而論,不失為系統管理員調整權值的參考依據之一。

IBM發表Blue Cloud 雲端運算進入商用市場
Blue Cloud包含刀鋒伺服器BaldeCenter、Tivoli負載管理軟體、Apache Hadoop平行處理規劃機制,和Xen、PowerVM的開放式Linux架構,並且支援IBM Power及x86平台。
IBM週四(11/15)於上海宣布Blue Cloud計畫,預計明年春季將首次把雲端運算(Cloud Computing)帶入商業應用市場。Blue Cloud包括刀鋒伺服器、機架伺服器和大型主機等方案。
IBM系統事業群研發暨製造資深副總Rod Adkins指出,雲端運算讓企業大大減少IT管理的複雜性和成本,尤其對導入Web 2.0應用相當有利。IBM認為,企業上網裝置快速增長,以及社群網路、行動運算、協同作業、混搭程式(mashups)等趨勢,都是加速雲端運算需求的主因。
Blue Cloud提供導入雲端運算的工具和服務,允許企業將運算任務分成不同組件,分別調至最有效率的電腦系統執行,解決企業尖鋒、離鋒時間的系統負荷量問題。
舉例來說,若紐約的證券經紀商需要用總部伺服器結算交易,可將後勤人員的運算任務派遣到分行伺服器上,達到節省時間和利用閒置資源的目的。
IBM表示,Blue Cloud包含刀鋒伺服器BaldeCenter、Tivoli負載管理軟體、Apache Hadoop平行處理規劃機制,和Xen、PowerVM的開放式Linux架構,並且支援IBM Power及x86平台。
除了刀鋒伺服器環境,IBM承諾明年將推出適合Z系列大型主機和機架式伺服器等環境使用的Blue Cloud。目前,越南科技部已決定採用Blue Cloud方案,正在進行系統測試。
為因應企業對大量運算的需求,雲端運算成為廠商積極投入的領域,包括IBM、HP、Sun和微軟都在發展相關計劃,其中IBM特別強調系統的自主管理能力。(編譯/黃品如)
分享至PLURK 噗浪
分享至FACEBOOK 臉書
IBM週四(11/15)於上海宣布Blue Cloud計畫,預計明年春季將首次把雲端運算(Cloud Computing)帶入商業應用市場。Blue Cloud包括刀鋒伺服器、機架伺服器和大型主機等方案。
IBM系統事業群研發暨製造資深副總Rod Adkins指出,雲端運算讓企業大大減少IT管理的複雜性和成本,尤其對導入Web 2.0應用相當有利。IBM認為,企業上網裝置快速增長,以及社群網路、行動運算、協同作業、混搭程式(mashups)等趨勢,都是加速雲端運算需求的主因。
Blue Cloud提供導入雲端運算的工具和服務,允許企業將運算任務分成不同組件,分別調至最有效率的電腦系統執行,解決企業尖鋒、離鋒時間的系統負荷量問題。
舉例來說,若紐約的證券經紀商需要用總部伺服器結算交易,可將後勤人員的運算任務派遣到分行伺服器上,達到節省時間和利用閒置資源的目的。
IBM表示,Blue Cloud包含刀鋒伺服器BaldeCenter、Tivoli負載管理軟體、Apache Hadoop平行處理規劃機制,和Xen、PowerVM的開放式Linux架構,並且支援IBM Power及x86平台。
除了刀鋒伺服器環境,IBM承諾明年將推出適合Z系列大型主機和機架式伺服器等環境使用的Blue Cloud。目前,越南科技部已決定採用Blue Cloud方案,正在進行系統測試。
為因應企業對大量運算的需求,雲端運算成為廠商積極投入的領域,包括IBM、HP、Sun和微軟都在發展相關計劃,其中IBM特別強調系統的自主管理能力。(編譯/黃品如)
Google最強武器 雲端運算
你聽過雲端運算(Cloud Computing)嗎?這不是複雜又難以親近的自然科學,而是你我日常生活中都會用到的技術,舉例來說,Google能在1秒鐘內搜尋超過全球1億個網頁,用的就是這種技術。在標榜著Web 2.0的現代,以前的不可能,現在看起來一切都很合理。
Web 2.0最終實現方式
你聽過雲端運算(Cloud Computing)嗎?這不是複雜又難以親近的自然科學,而是你我日常生活中都會用到的技術,舉例來說,Google能在1秒鐘內搜尋超過全球1億個網頁,用的就是這種技術。在標榜著Web 2.0的現代,以前的不可能,現在看起來一切都很合理。
無網路時代,電腦只是孤兒
大概在十年前,網路還不普及,即使有幸能與網際網路接軌,透過傳統電話數據機進行資訊交換,也會因為網路的工作內容有限造成阻礙。上網找資料?網站不夠多,也沒有Google這麼強大的搜尋引擎,跑圖書館反而是最實際的方法,使用最多的就只是電子郵件交換,加上電話連接網路的成本,也會讓你對使用時間長短「斤斤計較」。
而網路的不普及,也導致個人電腦使用主要是「單機運作」,文書處理、影像繪圖、科學計算全在一部電腦上獨立運作,因此個人電腦內硬體配備的好壞就變得非常重要。想要娛樂?在電腦看VCD(那時代還沒有DVD),遊戲就是單機版,要玩多人大富翁,你得聚集幾個朋友搬些椅子在電腦前,大家輪流透過同一組鍵盤滑鼠操作。在沒有網際網路連線的時代,組一台電腦都很昂貴,何況是組成一個簡單的區域網路更加不可能。
你知道終端機嗎?
讀完前面的段落,或許很多資深玩家會抗議怎麼漏掉了BBS站這個最重要的「網路應用」。BBS站又稱為「電子佈告欄」,主要是提供文字模式的訊息交換平台,申請BBS站的帳號後,你可以在佈告欄留言,或加入某個主題進行討論(有點類似現在的討論區),還可跟特定的網友用「站內信」交換意見,所有的工作只要用軟體連線到指定電腦,就可以開始作業,包括編輯文字訊息、接收站內信,都是在遠端主機中,這就是很簡單的終端機概念,資料不在你的電腦內,你只是用指令在操作遠端的電腦幫你做事情。千萬別小看這場景,它可具備了雲端運算的基本概念「運算的工作在遠端電腦進行,本機只是負責單純的操作」;只是以現在的眼光來看,用BBS來比喻雲端運算未免太小題大作,因為BBS的資料量很小,只是單純的文字字元,沒有複雜的圖形處理工作,或者龐大的數據運算需求,還不構成近代「雲端運算」的規模。
雲端運算技術讓Google在短短0.16秒內就可以找到378,000個與搜尋字串有關的網站
也許你體驗過雲端運算
隨著網路的發展快速,傳輸頻寬也越來越大,最慢的1M ADSL比起56K數據機都快上近20倍,網路能做的事情更多了。Google為大家做了網路無限可能的示範,你用過Gmail、Google Docs、Google Talk、iGoogle、Google Calendar等線上應用嗎?這就是雲端運算的基礎運用!瀏覽器連上指定的網站,就能開始編輯文件然後「線上」存檔,在公司沒寫完的稿子,回家還可以連上網路繼續寫;Google Spreadsheet圖形化的線上試算表,定義公式後填入數值,計算工作都是靠Google主機內的處理器;這些工作與我們使用的電腦性能無關,只有網路連接速度是問題。
其實上面的概念,昇陽在90年代末期就提出過「網路電腦」的構想,並且有實體產品問世,可惜的是當時沒有隨地寬頻,若得把工作交由遠端主機處理,再用網路回傳到本機的速度恐怕不是一般人所能接受。另一方面,一般用途的雲端運算,現在能成功的因素還包含介面設計的成功,以Google為例,Ajax設計的人性化介面,只要會在瀏覽器輸入網址就會使用。但昇陽的初期產品,需要用專屬的機器、作業系統,整個架構部署後所費不貲。
Google Docs是線上的文書處理軟體,只要瀏覽器操作,連安裝都不需要
企業、科學用途的雲端運算
一般我們能接觸到的只是簡單的雲端運算應用,最複雜的程度也只到影片轉檔處理,YouTube應該算是以筆者能力用到最複雜的項目。自己的影片用網路傳遞給YouTube,然後透過他們的伺服器轉換影片成FLV格式,最後決定要不要公開分享。企業與科學用途的雲端運算,處理的項目通常是龐大的數據計算,例如生產排程工作,龐大的生產線加上一堆限制條件(可能是幾十萬條限制),需要在短時間內獲得結果,所以使用者介面變得不是重點,負責運算的機器是否快速又穩定比較重要。藉助雲端運算,企業只要在本地送出運算式,交由他處強大的超級電腦運算,經過高速計算後得到最佳解決。
商用雲端運算主要應用有線性規劃、統計分析,科學用途的最經典的應用就是生物科學,例如分析DNA結構、基因圖譜定序、解析癌症細胞等,用他處的高速主機協助,比自己單機運算還有效率。對於企業與科學研究而言,雲端運算的導入能大幅降低成本,不必購置昂貴的超級電腦,與負擔後續的維護成本加上設備折舊費用,只要把運算的原始資料交由市場上專業的處理公司,依照處理器耗費的資源或時間付費。
未來的資訊發展趨勢
雲端運算的出現,衝擊最大的就是傳統個人電腦市場,不管是硬體製造商或是作業系統開發者(尤其是個人用戶為主的微軟),未來只要準備一台有瀏覽器的設備,就能達成需要的一般性工作,何必每年升級電腦,或者跟隨廠商的腳步升級作業系統?雲端運算的模式,等於是把資訊產業慢慢傾向服務業的性質,工作平台由業者的網路平台提供,使用者的電腦變成只是溝通的工具、現代化的圖形終端機。
分散式系統、平行處理、大型主機等資訊科學理論,造就了現代的雲端運算,如何有效的分配運算效能,並節約能源是擁有雲端平台業者所需思考的議題,身為普通電腦使用者的我們,會因為網路頻寬提升在未來有更多功能可使用。或許等到光纖寬頻100M/100M網路達成的那天,會不會Maya、Photoshop這類大型的動畫、影像處理軟體,說不定不需發行實體光碟,只要賣給用戶網站的使用帳號,用戶在業者的線上平台作業,就能解決所有工作需求。
【digitalhome 第103期 1月號】
分享至PLURK 噗浪
分享至FACEBOOK 臉書
Web 2.0最終實現方式
你聽過雲端運算(Cloud Computing)嗎?這不是複雜又難以親近的自然科學,而是你我日常生活中都會用到的技術,舉例來說,Google能在1秒鐘內搜尋超過全球1億個網頁,用的就是這種技術。在標榜著Web 2.0的現代,以前的不可能,現在看起來一切都很合理。
無網路時代,電腦只是孤兒
大概在十年前,網路還不普及,即使有幸能與網際網路接軌,透過傳統電話數據機進行資訊交換,也會因為網路的工作內容有限造成阻礙。上網找資料?網站不夠多,也沒有Google這麼強大的搜尋引擎,跑圖書館反而是最實際的方法,使用最多的就只是電子郵件交換,加上電話連接網路的成本,也會讓你對使用時間長短「斤斤計較」。
而網路的不普及,也導致個人電腦使用主要是「單機運作」,文書處理、影像繪圖、科學計算全在一部電腦上獨立運作,因此個人電腦內硬體配備的好壞就變得非常重要。想要娛樂?在電腦看VCD(那時代還沒有DVD),遊戲就是單機版,要玩多人大富翁,你得聚集幾個朋友搬些椅子在電腦前,大家輪流透過同一組鍵盤滑鼠操作。在沒有網際網路連線的時代,組一台電腦都很昂貴,何況是組成一個簡單的區域網路更加不可能。
你知道終端機嗎?
讀完前面的段落,或許很多資深玩家會抗議怎麼漏掉了BBS站這個最重要的「網路應用」。BBS站又稱為「電子佈告欄」,主要是提供文字模式的訊息交換平台,申請BBS站的帳號後,你可以在佈告欄留言,或加入某個主題進行討論(有點類似現在的討論區),還可跟特定的網友用「站內信」交換意見,所有的工作只要用軟體連線到指定電腦,就可以開始作業,包括編輯文字訊息、接收站內信,都是在遠端主機中,這就是很簡單的終端機概念,資料不在你的電腦內,你只是用指令在操作遠端的電腦幫你做事情。千萬別小看這場景,它可具備了雲端運算的基本概念「運算的工作在遠端電腦進行,本機只是負責單純的操作」;只是以現在的眼光來看,用BBS來比喻雲端運算未免太小題大作,因為BBS的資料量很小,只是單純的文字字元,沒有複雜的圖形處理工作,或者龐大的數據運算需求,還不構成近代「雲端運算」的規模。
雲端運算技術讓Google在短短0.16秒內就可以找到378,000個與搜尋字串有關的網站
也許你體驗過雲端運算
隨著網路的發展快速,傳輸頻寬也越來越大,最慢的1M ADSL比起56K數據機都快上近20倍,網路能做的事情更多了。Google為大家做了網路無限可能的示範,你用過Gmail、Google Docs、Google Talk、iGoogle、Google Calendar等線上應用嗎?這就是雲端運算的基礎運用!瀏覽器連上指定的網站,就能開始編輯文件然後「線上」存檔,在公司沒寫完的稿子,回家還可以連上網路繼續寫;Google Spreadsheet圖形化的線上試算表,定義公式後填入數值,計算工作都是靠Google主機內的處理器;這些工作與我們使用的電腦性能無關,只有網路連接速度是問題。
其實上面的概念,昇陽在90年代末期就提出過「網路電腦」的構想,並且有實體產品問世,可惜的是當時沒有隨地寬頻,若得把工作交由遠端主機處理,再用網路回傳到本機的速度恐怕不是一般人所能接受。另一方面,一般用途的雲端運算,現在能成功的因素還包含介面設計的成功,以Google為例,Ajax設計的人性化介面,只要會在瀏覽器輸入網址就會使用。但昇陽的初期產品,需要用專屬的機器、作業系統,整個架構部署後所費不貲。
Google Docs是線上的文書處理軟體,只要瀏覽器操作,連安裝都不需要
企業、科學用途的雲端運算
一般我們能接觸到的只是簡單的雲端運算應用,最複雜的程度也只到影片轉檔處理,YouTube應該算是以筆者能力用到最複雜的項目。自己的影片用網路傳遞給YouTube,然後透過他們的伺服器轉換影片成FLV格式,最後決定要不要公開分享。企業與科學用途的雲端運算,處理的項目通常是龐大的數據計算,例如生產排程工作,龐大的生產線加上一堆限制條件(可能是幾十萬條限制),需要在短時間內獲得結果,所以使用者介面變得不是重點,負責運算的機器是否快速又穩定比較重要。藉助雲端運算,企業只要在本地送出運算式,交由他處強大的超級電腦運算,經過高速計算後得到最佳解決。
商用雲端運算主要應用有線性規劃、統計分析,科學用途的最經典的應用就是生物科學,例如分析DNA結構、基因圖譜定序、解析癌症細胞等,用他處的高速主機協助,比自己單機運算還有效率。對於企業與科學研究而言,雲端運算的導入能大幅降低成本,不必購置昂貴的超級電腦,與負擔後續的維護成本加上設備折舊費用,只要把運算的原始資料交由市場上專業的處理公司,依照處理器耗費的資源或時間付費。
未來的資訊發展趨勢
雲端運算的出現,衝擊最大的就是傳統個人電腦市場,不管是硬體製造商或是作業系統開發者(尤其是個人用戶為主的微軟),未來只要準備一台有瀏覽器的設備,就能達成需要的一般性工作,何必每年升級電腦,或者跟隨廠商的腳步升級作業系統?雲端運算的模式,等於是把資訊產業慢慢傾向服務業的性質,工作平台由業者的網路平台提供,使用者的電腦變成只是溝通的工具、現代化的圖形終端機。
分散式系統、平行處理、大型主機等資訊科學理論,造就了現代的雲端運算,如何有效的分配運算效能,並節約能源是擁有雲端平台業者所需思考的議題,身為普通電腦使用者的我們,會因為網路頻寬提升在未來有更多功能可使用。或許等到光纖寬頻100M/100M網路達成的那天,會不會Maya、Photoshop這類大型的動畫、影像處理軟體,說不定不需發行實體光碟,只要賣給用戶網站的使用帳號,用戶在業者的線上平台作業,就能解決所有工作需求。
【digitalhome 第103期 1月號】
訂閱:
文章 (Atom)